Квартиры улучшенной планировки — понятие и преимущества. Жми!
Еще со времен Советского Союза известны различные модификации квартир. Такие названия, как «брежневка», «сталинка» или «хрущевка» у многих владельцев жилья на слуху, когда речь заходит о его продаже, обмене или покупке.
Оказывается, не все будущие собственники жилплощади имеют понятие о том, чем же существенно различаются планы квартир.
В этой статье мы рассмотрим такое понятие, как квартира улучшенной планировки или «улучшенка».
Особенности жилплощади улучшенной планировки
По сравнению с жилплощадью обычной планировки улучшенное жилье имеет ряд преимуществ, которые выгодно отличают его:
- Раздельный санузел.
- Просторные комнаты с высоким (до 2,5 м) потолком.
- Наличие лоджии (в некоторых случаях и двух).
- Увеличенная площадь кухни (9 и более кв. м).
В настоящее время, в бум строительства комфортного жилья, помимо выше перечисленных особенностей, «улучшенка» может иметь и другие преимущества.
В улучшенных вариантах, имеющих 2 и более комнаты, нередко есть дополнительные помещения:
- второй санузел;
- гардеробная;
- кладовая.
Преимущества «улучшенки»
Современные застройщики предлагают немало комфортных и оригинальных решений для обустройства квартиры своей мечты. Однако, жилье индивидуальной планировки далеко не всем по карману, так как относится к разряду дорогостоящих.
В этом случае жилплощадь улучшенной планировки идеальный вариант для любой семьи. Чем же она отличается от бюджетных вариантов жилья со стандартной планировкой?
Приведем некоторые отличия:
- Дом, как правило, построен из кирпича, а не из панельных конструкций.
- Подъезды домов оборудованы грузовым лифтом и мусоропроводом.
- Комнаты ориентированы на свет с максимальным комфортом для проживающих.

- Наличие встроенных шкафов.
- Широкие проходы между комнатами и другими помещениями.
- Дополнительные балконы, если квартира имеет более 2-х комнат.
- Улучшенная шумовая изоляция.
- Раздельное расположение комнат.
- Возможности к перепланировке жилья.
Между тем, стоимость той же «хрущевки» практически приравнивается к расценкам на квартиры улучшенной планировки, но последняя выгодно отличается от стандартных вариантов.
Именно поэтому, тем, кто еще не определился, что ему выбрать, рекомендуем остановить свой выбор на оптимальном варианте — квартире улучшенной планировки.
Смотрите видео-обзор квартиры улучшенной планировки:
Внимание!
Наши статьи рассказывают о типовых способах решения юридических вопросов,
но каждый случай носит уникальный характер.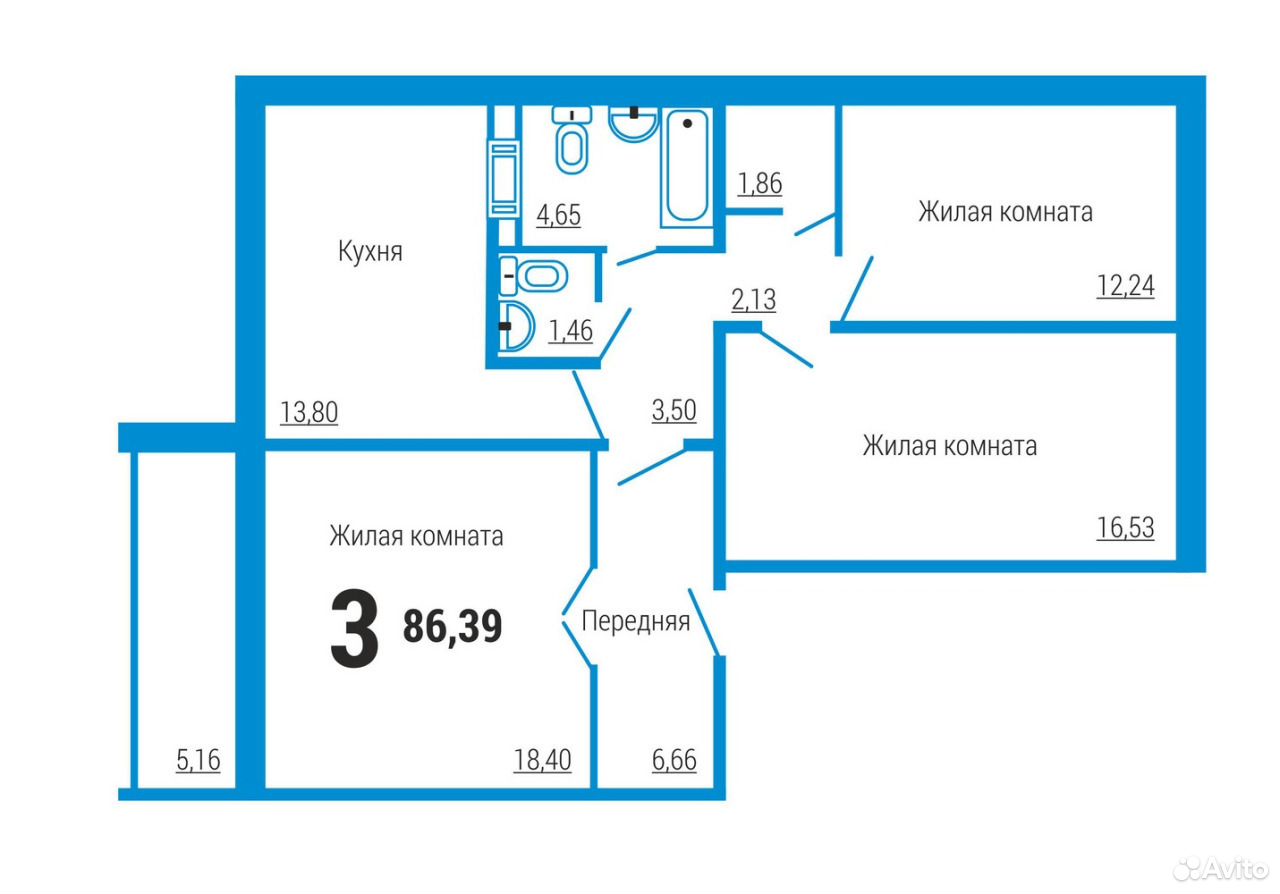 Если вы хотите узнать,
как решить именно Вашу проблему — звоните по телефонам:
Если вы хотите узнать,
как решить именно Вашу проблему — звоните по телефонам:
+7(499) 703-42-21 — Москва
+7(812) 309-91-17 — Санкт-Петербург
+7(800) 500-27-29 доб. 482 — Россия (общий)
или если Вам так удобнее, воспользуйтесь формой онлайн-консультанта ниже!
Все консультации у юристов бесплатны.
Еще статьи по теме:
Планировка 5-комнатной квартиры: 45 фото
Считается, что обустроить малогабаритное жильё сложнее, чем полнометражное. Но это не совсем верно. Планировка 5-комнатной квартиры – обычной, не элитной – предназначена для проживания 4-5 человек.
У каждого свой взгляд на комфорт и эстетику окружающего пространства, поэтому прийти к общему знаменателю гораздо сложнее.
Вернуться к оглавлениюСодержание материала
Планировочные решения
У квартир с пятью жилыми комнатами большой диапазон размеров: от 110 до 280 кв. м. У каждой планировки свои особенности, поэтому рассмотрим жильё по категориям.
м. У каждой планировки свои особенности, поэтому рассмотрим жильё по категориям.
Малогабаритные (эконом-сегмент) квартиры
Многое зависит от года постройки дома. В хрущёвках (60-70-е годы) такие квартиры встречаются редко, а у тех что есть, площадь 115-125 м2.
Изначально они предназначались для многодетных семей.
Почему на такой небольшой площади поместилось 5 комнат? Да потому, что они очень маленькие (спальни 9-12 кв. м), как в малосемейках.
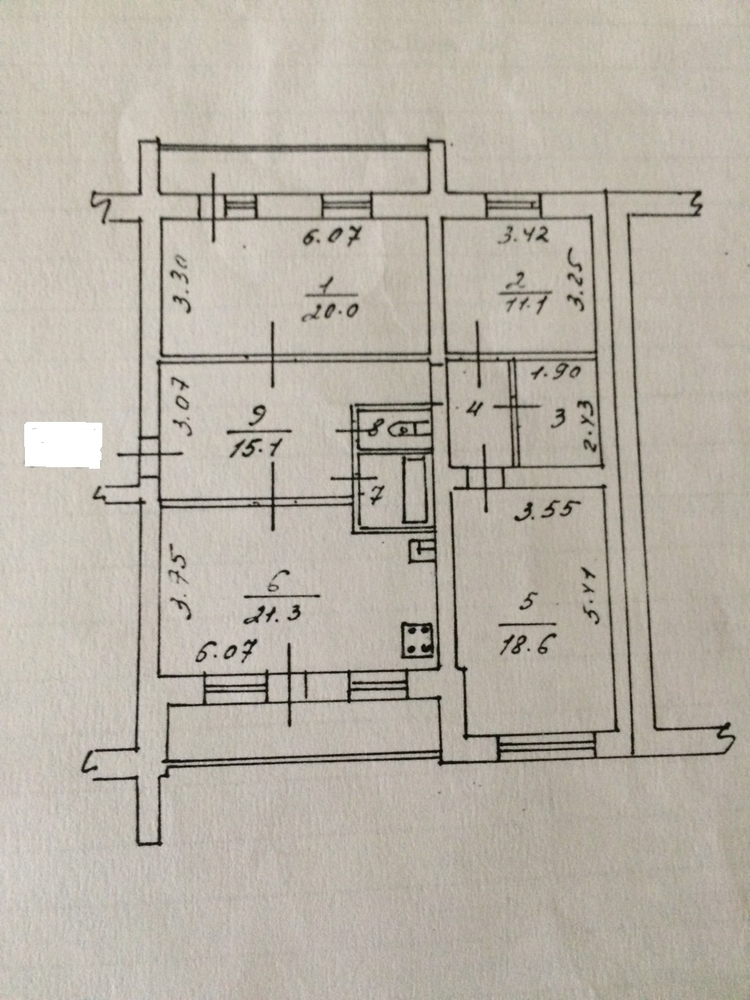
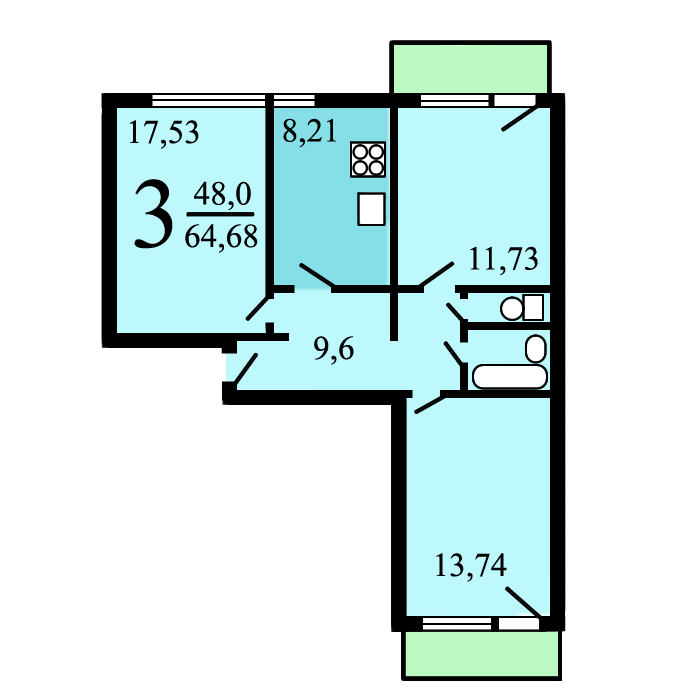
Планировка 5 комнатной квартиры с малым метражом
Выше представлен типовой вариант планировки таких квартир. Здесь она круговая, комнаты расположены вокруг центрального коридора. Помещения маленькие, но почти квадратные, что не вызывает проблем с установкой мебели.
Кухню в 11 кв. м тоже не назовёшь просторной, если учесть, что за стол одновременно будет садиться пять, а то и шесть человек.
Пространство кухни 11 м2 выглядит примерно так
Санузлов в квартире два: один совмещённый, и отдельный туалет.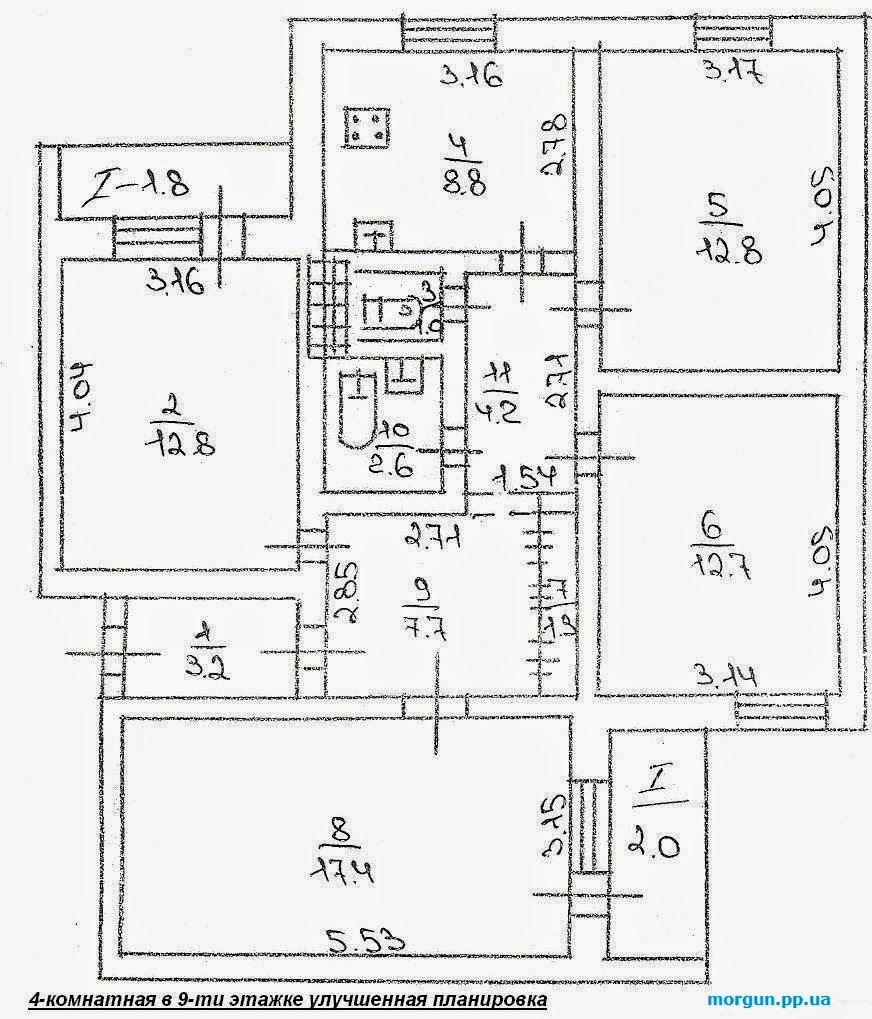 Одной ванной на 5 человек недостаточно. Да и та, что есть, слишком маленькая.
Одной ванной на 5 человек недостаточно. Да и та, что есть, слишком маленькая.
Зато есть две кладовые. Ту, что соседствует с гостевым туалетом, можно переделать под ванную или, убрав перегородку между ними, сделать ещё один совмещённый санузел.
К достоинствам этой квартиры можно отнести две просторные лоджии, на которых многие устраивают рабочие места для школьников
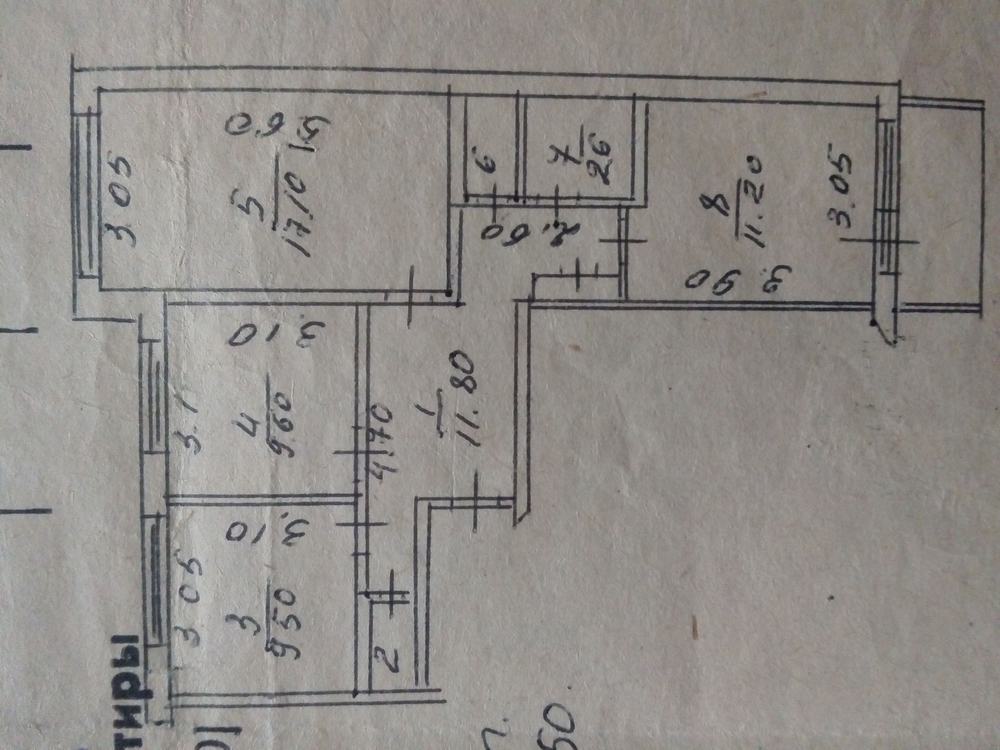
Ниже представлена ещё одна планировка пятикомнатной квартиры малого метража. По конфигурации она Г-образная, составлена из отдельно купленных и соединённых при перепланировке двухкомнатной и трёхкомнатной квартир.
А что было делать многодетным семьям, если подходящего по площади жилья в советские времена почти не строили?
Планировка при таком объединении получается неплохой: и комнат достаточно, и есть два совмещённых санузла. Только не всегда понятно, что делать с двумя кухнями.
На примере внизу видно, что обе кухни имеют площадь, достаточную, чтобы одну из них переделать под спальню.
Пятикомнатная квартира из двушки и трёшки
Вторую кухню можно объединить с соседней комнатой, убрав перегородку совсем, или сделав проём. Получится полноценная кухня-столовая, в которой за обедом с комфортом поместится всё семейство.
Варианты зонирования кухни представлены в статье на нашем сайте.
Выглядеть это может примерно так:
А вот ещё одна не совсем обычная планировка. Квартира напоминает по форме сапожок, срединную часть которого занимает прихожая, а угловую – гостиная.
Помещения расположены компактно, никто друг другу не мешает, что особо ценно, если дом панельный с хорошей слышимостью.
Есть в этой планировке и вспомогательные помещения: кладовка, гардеробная, два нормальных по размеру совмещённых санузла.
Такая планировка встречается нечасто
В целом всё замечательно. Да и лишних денег за такое жильё платить не придётся. И будет проще делать ремонт квартиры и уборку.
Улучшенная планировка (класс комфорт)
Позднее, уже в брежневские времена, появилось понятие «улучшенная планировка».
Коснулось оно и многокомнатных квартир, площадь которых подросла до 122-135 м2. Лишних 12 квадратов – это уже плюс по паре метров к каждой комнате.
При этом увеличивается и площадь кухни, в которой есть место для полноценной столовой зоны.
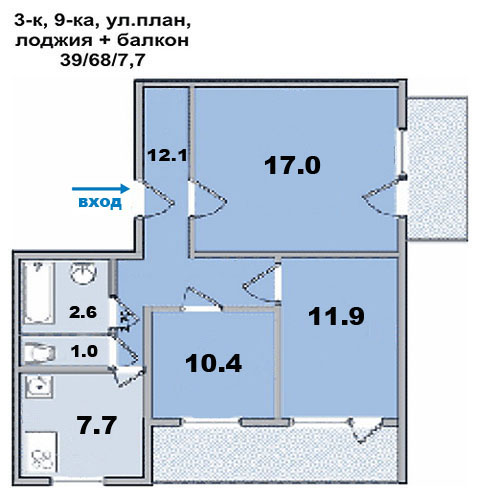
Квартира с двумя эркерами
Выше представлена такая квартира улучшенной планировки. В числе её достоинств просторные комнаты и два эркера, которые дают много возможностей для создания интерьера.
И всё бы хорошо в этой квартире, да только ванная комната очень маленькая, всего 2,9 м2. Хотя есть отдельный туалет. На 5 человек это очень мало, квартиры брежневской эпохи часто тем и грешили.
А вот ниже квартира такой же площади, но с другим планировочным решением.
Площадь та же, планировка более удобная
Кухня здесь не 17 м2, как в предыдущем примере, а 12, но она сообщается проёмом с гостиной, в которой можно устроить столовую зону.
Варианты планировки кухни на 12 м2смотрите по ссылке.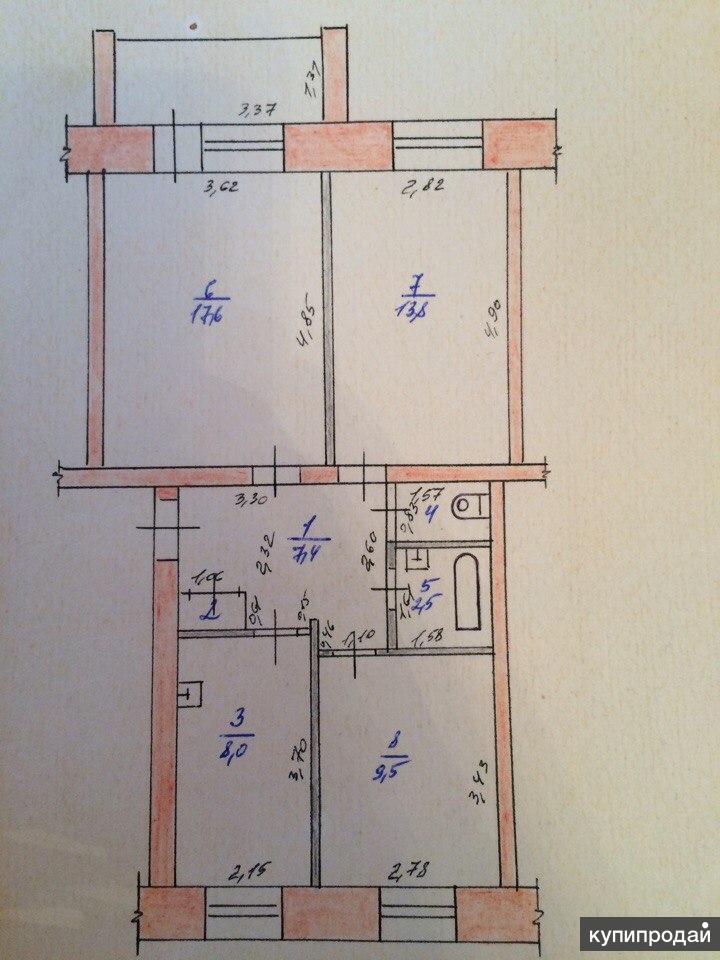
Столовая зона в гостиной
Зато эта разница в 5 м2 дала возможность сделать не тесную ванную, а большой совмещённый санузел 9,5 м2. Отдельный туалет тоже есть.
В таком помещении кроме ванной можно установить ещё и душевую кабину.
Бизнес-класс
Ещё один вариант улучшенной планировки квартиры с пятью жилыми помещениями, но теперь с площадью 150 м2.
Особенность первого варианта – Г- образное расположение комнат. Есть эркер и большая лоджия.
Идеально удобная 5-комнатная квартира
Гостиная ближе к входной двери, вход в неё из прихожей и из кухни с примыкающим к ней гостевым туалетом.
Идеи планировки и оформления коридора в квартире смотрите по ссылке.
Далее парами на противоположные стороны расположены 4 спальни с ванной и ещё одним туалетом между ними.
Эта планировка отлично продумана и очень удобна. В ней грамотно распределена площадь квартиры, что встречается далеко не во всех типовых проектах.
Ниже пример плохого планировочного решения, когда в квартире такой же площади поместилось всего 4 комнаты средней площадью среднем 20 м 2. Для спален столько места не требуется.
Площадь та же, но комнат всего 4
Из двух соседних спален общей площадью 40 м2, можно сделать три поменьше. На 13 м2 разместится всё, что нужно одному взрослому человеку или двум детям: кровать, шкаф для одежды,с компьютером.
А вот места общего пользования должны быть более просторными.
В новостройках часто встречаются двухуровневые квартиры с пятью комнатами. Внизу обычно располагается зона дневного пребывания и одна спальня, вверху – только спальни. Санузлы есть на обоих этажах.
Вот несколько примеров таких квартир:
Элитные (премиум)
Далеко не всегда пятикомнатные квартиры покупают многодетные семьи.
Такое жильё привлекательно и для людей с достатком, позволяющим кроме своих спален иметь ещё и пару гостевых. Для таких клиентов проектируют дома, которые на рынке недвижимости принято называть элитными.
В этой квартире около 200 м2, но не факт, что её можно отнести к элитной недвижимости
Разница между ними и обычным жильём начинается уже с площади, которая почти вдвое превышает метраж квартир сегмента эконом или комфорт.
Хотя бесспорных критериев, позволяющих классифицировать такое жильё, практически нет. У застройщиков они свои, у риэлторов свои, а покупатель порой не понимает, то ли он покупает подозрительно дешёвое элитное жильё, то ли переплачивает за бизнес-класс.
Признаки элитного жилья
Чтобы провести более чёткую границу между дорогой и обычной недвижимостью, специалисты решили проанализировать качество домов по нескольким параметрам.
Элитная новостройка
Был составлен список признаков жилья, позволяющего отнести его к категории элитного:
- Здание дома историческое, с сохранением первоначального фасада, или современный авторский проект.
- Эксклюзивная планировка квартир, которых, в зависимости от размера, на этаже (а то и во всём подъезде) будет не более четырёх. Планировочные решения могут быть традиционными с отдельными спальнями или студийного типа.
- Кухня не объединяется с комнатами. Она отдельная, площадью не менее 20 м2.
- Высота потолков не менее трёх метров.
- Никаких пластиковых стеклопакетов. Окна, межкомнатные двери и рамы на балконе только из твёрдых пород дерева.
- В элитных домах свой подземный паркинг, в котором минимум одно место на квартиру.
- На входе в подъезд есть ресепшен, в котором сидит не бабушка-консьерж, а охранник, осуществляющий видеонаблюдение.
- Инженерное оснащение таких домов выполняется по последнему слову техники. В них не бывает перебоев с горячей водой и светом, так как есть автономный генератор и тепловой пункт. Осуществляется кондиционирование, и, как правило, внедрена система умного дома.
- Даже если дом не в центре города, у него всё равно нет проблем с инфраструктурой. Для собственного пользования жильцов в таких комплексах есть спа-салоны, рестораны, детские сады.
- Территория комплекса и придомовые участки – это не просто асфальтированный двор, а проектируемое пространство, организованное усилиями ландшафтного дизайнера.
 Планировочные решения могут быть традиционными с отдельными спальнями или студийного типа.
Планировочные решения могут быть традиционными с отдельными спальнями или студийного типа.
Ландшафт элитного комплекса
Особенности планировки
Так как элитные дома строятся по авторским проектам, они всегда единственные в своём роде. А значит, и планировки везде индивидуальные.
Часто фасады таких домов почти полностью остекляемые, поэтому почти в каждой комнате есть лоджия, а в санузлах – окна на улицу.
Сама квартира может быть одно- или двухуровневой. Площадь от 170 до 270 м2.
Дизайн такой квартиры обычно выполняют по проекту. Автор предварительно выясняет предпочтения собственников, желаемый архитектурный стиль, учитывает род занятий и образ жизни владельца и предлагает на выбор несколько вариантов.
Вот как это может выглядеть в реальности:
Смотрите в видео: планировка и дизайн пятикомнатной квартиры.
 com/embed/u26Q278oPkM» frameborder=»0″ allowfullscreen=»allowfullscreen»/>
com/embed/u26Q278oPkM» frameborder=»0″ allowfullscreen=»allowfullscreen»/>Планировки однокомнатной квартиры фото с размерами
Типовая планировка реализуется в нескольких вариантах:
- Стандартная.
- Угловая квартира с окнами.
- Квартира с нишей (нишами).
- Нестандартная архитектура.
- Студия.
Площадь может быть разной: от 30-38 м2 до 40-45 м2 и более.
При обустройстве квартиры c типовой планировкой решаются такие строительно-ремонтные и дизайнерские проблемы, как:
- Отделка всех внутренних поверхностей, включая стены, потолки, перегородки, пол.
- Расстановка мебели и бытовой электроники.
- Преобразование всех отрицательных моментов планировки в преимущества помещения.
Типовая схема однокомнатной квартиры устроена таким образом, что в ней комфортно 1-3 людям, но чаще в стесненных условиях живут семьи с несколькими детьми или престарелыми родителями. При большом количестве человек зонирование площади проводится более тщательно, и для этого составляется архитектурный и дизайнерский план. Пример перепланировки большой квартиры с одним главным помещением
Пример перепланировки большой квартиры с одним главным помещением
Дизайн-проект состоит из таких пунктов, как:
- План помещений квартиры с учетом архитектуры (наличие ниш, вентиляционных каналов, и т.д.).
- Схема инженерных коммуникаций.
- Расположение мебели и других предметов интерьера.
- Оценка стройматериалов для перепланировки и ремонта помещений.
- Оценка стоимости трудозатрат – собственных или нанятой бригады.
Подготовленный дизайнерский план предполагает начало работ по ремонту и перепланировке. Сюда могут входить замена окон и дверей, теплоизоляция внутренних поверхностей, замена коммуникаций и сантехнических приборов, подготовка стен, потолка, пола к ремонту. Кроме того, такой план подразумевает выбор стиля, в котором будет оформлена вся квартира, и для этого подбираются стройматериалы, предметы мебели и элементы внутреннего декора.
Особенности планировки
Недостатки планировки 1-комнатной квартиры:
- Небольшая жилая площадь.
- Очень часто – низкий потолок.
- Маленький туалет, ванная комната и кухня.
- Маленький коридор или прихожая.
- Нет антресолей.
- Часто нет балкона или лоджии.
Главное преимущество квартиры, расположенной не на углу дома, а внутри, является ее намного лучшее сохранение тепла. Кроме того, существует несколько непреложных правил, которые применяются при планировке:
- Старый дизайнерский прием – необходимо визуально показать как можно больше свободного места в комнате.
- Обильное искусственное освещение даже при наличии достаточного естественного освещения.
- Использование комбинаций цвета. Например, потолок всегда должен быть светлее остальных поверхностей, но его не обязательно делать белым – он может быть любого цвета. Более светлый потолок визуально приподнимется и сделает помещение просторнее.
- Зеркала и глянцевые отражающие поверхности в интерьере также позволят визуально увеличить комнату.
- В однушке предпочтительнее использовать стиль дизайна минимализм – он сделает комнату просторнее и сохранит ее функциональные особенности.
- Встроенная или мобильная мебель.
- Вместо стационарной внутренней перегородки между помещениями рекомендуется установить мебель – шкаф, стеллаж. Она будет выполнять не только роль перегородки, но и свои непосредственные функции.

Угловая
Обязательное правило, которое должно быть отражено, – реализация светлого дизайна. Это не значит, что все предметы и поверхности должны быть белыми – тона и оттенки могут компоноваться и даже контрастировать друг с другом, но преобладающий цвет – светлый. Яркие цвета в небольших количествах также великолепно дополнят дизайн маленькой квартиры. Глянцевые, зеркальные и стеклянные поверхности визуально увеличат площадь комнаты, так как отражают интерьер, расширяя границы квартиры.
Стеклянная, пластиковая прозрачная мебель сделает пространство воздушным, незагроможденным, поэтому дизайнеры настоятельно рекомендуют ее к эксплуатации. Высокие шкафы с антресолями увеличат функциональность и сэкономят пространство в квартире, а также послужат элементом зонирования помещения, отделяя, например, спальню от зоны дневного отдыха. Этажерки или стеллажи с полками без задних стенок для угловой квартиры – находка, ведь они зонируют пространство, сохраняя общую функциональность.
Схема угловой однушки
Высокие шкафы с антресолями увеличат функциональность и сэкономят пространство в квартире, а также послужат элементом зонирования помещения, отделяя, например, спальню от зоны дневного отдыха. Этажерки или стеллажи с полками без задних стенок для угловой квартиры – находка, ведь они зонируют пространство, сохраняя общую функциональность.
Схема угловой однушки
Прямоугольная
Квартиры с открытым дизайном – это идеальный вариант для проживания одного человека или семьи без детей. Чтобы обеспечить максимальное удобство, необходимо составить план расположения мебели, осветительных приборов и прокладки инженерных коммуникаций. Студии наиболее востребованы на рынке недвижимости, так как имеют множество преимуществ.
Однокомнатные квартиры прямоугольной формы – это:
- Свободная архитектура.
- Стандартная планировка.
- Квартира-студия.
Достоинства и недостатки студий:
| Достоинства | Недостатки |
| Обильное естественное освещение | Маленькая площадь |
| Нет внутренних перегородок | Отсутствие балкона |
| Монопространство | Сложный дизайн и архитектура |
| Подходящие акустические характеристики | Подходящие акустические характеристики |
| Облегченная уборка помещения | Наличие сквозняков, что требует монтажа дополнительной вентиляции |
| Выгодная аренда комнаты |
Чтобы квартира-студия не только служила жильем, но и была при этом комфортной, в ее дизайне применяют самые современные технологии. Прежде всего, это зонирование, которое позволит без изолирования разделить одну комнату на несколько – рабочую, зону отдыха, приема и приготовления пищи и т.д.
Прежде всего, это зонирование, которое позволит без изолирования разделить одну комнату на несколько – рабочую, зону отдыха, приема и приготовления пищи и т.д.
Зона отдыха традиционно обустраивается рядом с окном, обеденная – около стены, спальню можно изолировать неполной перегородкой, как и ванную. Прихожую обозначают вешалкой, столиком, комодом для обуви, небольшим шкафом для верхней одежды. 3-D визуализация однокомнатной прямоугольной квартиры-студии
Квадратная
Квадратная квартира – это жилье в хрущевке с прямоугольной комнатой в 16-18 м2, кухней, коридором и туалетом, совмещенным с ванной. Обычно они подвергаются радикальной перепланировке. Например, кухню совмещают с основной комнатой, ванную – с туалетом, если они разделены.
Здесь очень маленький коридор, поэтому часто перегородку между ним и комнатой сносят для свободного доступа на кухню. Мебель подойдет минималистичная, лучше светлая.
Хороший дизайнерский прием – совмещение разных типов отделки поверхностей: штукатурка, плитка, обои.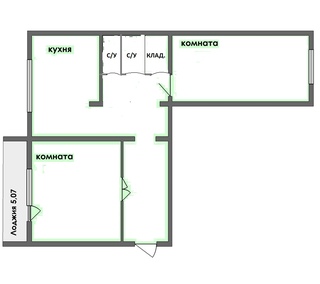
Стандартная квадратная однушкаВажно: Покупайте отделочные и ремонтные стройматериалы во влагостойком варианте, потому что близкое соседство ванной комнаты и туалета (помещений с повышенной влажностью) может вызвать деформации остальных стройматериалов и даже мебели.
Квартира с одной комнатой площадью 20 кв. м
Некоторые из методов планировки:
- Совмещение разных зон в одной комнате.
- Визуальное увеличение пространства.
- Минимализм во всем.
- Использование мебели-трансформера.
Основные помещения:
- Прихожая со встроенной мебелью.
- Совмещенный санузел.
- Кухня-столовая.
- Жилая зона с диваном-трансформером.
Проектирование квартир по кв. м
Варианты на первичном и вторичном рынке недвижимости:
- Сталинка – общая площадь 32-50 м2 у однушки. Потолок высотой (3 м) и встроенные шкафы. Санузел раздельный или совмещенный.
- Хрущевка – малогабаритное жилье с некомфортной планировкой. Потолок высотой 2,5-2,7 м, санузел, совмещенный с ванной, внутренние перегородки с плохой шумоизоляцией. Общая площадь – до 33 м2.
- Брежневка имеет изолированные помещения с окнами по разным сторонам дома. Есть место для встраивания прихожей. В однушке обычно совмещенный санузел, стены дома – ж/б, общая площадь – до 40 м2.
- Стандартная квартира имеет удобную планировку, часто с эркерами. Потолок высотой 2,5-2,8 м, раздельный санузел, большая кухня, лоджия, встроенные шкафы и кладовки-ниши, общая площадь – до 50 м2.
- Квартира улучшенной планировки имеет потолок высотой 2,5 м, помещения изолированные, раздельный санузел, лоджия, встроенные шкафы и антресоли, общая площадь – до 50 м2.
- Современная квартира имеет просторные помещения в панельном доме независимо от их функционального предназначения. Потолок высотой 2,8 м, санузел раздельный, общая площадь – до 80 м2.
 Санузел раздельный или совмещенный.
Санузел раздельный или совмещенный.
Жилье 20 кв. м
Зональность:
- Зал может служить спальной комнатой.
- Гостиную совмещают с кухней, рабочим кабинетом или спальней.
- На кухне, в гостиной и столовой располагают зону отдыха.
- Рабочий кабинет можно оборудовать на балконе.
Квартиры 25 кв. м
Функциональные зоны: гостиная, кухня, место для прихожей и спальни. Санузел совмещенный. В таких небольших комнатах спальню невозможно отгородить от гостиной, поэтому чаще всего используют диван-трансформер. Хороший прием – напротив окна расположить зеркало или другую отражающую поверхность, даже большой телевизор или стеклянный журнальный столик. Квартира 25 м2
Жилая площадь 31 кв. м
Основная задача в малогабаритных квартирах – деление пространства на зоны. Для предварительной визуализации существует специальная программа, например, АвтоКАД или 3D MAX. На площади в 31 м2 можно разместить гостиную, кухню с электроплитой, столовую зону. В санузле, на полу и отдельных стенах можно положить кафель большого размера. Существующие ниши используют для гардеробной и зоны хранения.
На площади в 31 м2 можно разместить гостиную, кухню с электроплитой, столовую зону. В санузле, на полу и отдельных стенах можно положить кафель большого размера. Существующие ниши используют для гардеробной и зоны хранения.
Комната 32 кв. м
Увеличить пространство можно объединением кухонной зоны и жилого помещения. Для планировки квартиры 32 кв. м необходимо:
- Обозначить места нахождения функциональных зон.
- Выбрать концепцию дизайна, чтобы разработать линию интерьера.
Проект 33 кв. м
Как и в предыдущих вариантах, предпочтительнее сделать квартиру-студию. Дизайнерские приемы позволяют совмещать как отдельные предметы мебели, так и помещения. Существует решение по трансформации стен, используются приподнимающиеся раскладные кровати, убирающиеся в шкафы телевизоры, а мебель используется для хранения самых разных предметов.
Стены-трансформеры в небольшом помещении
Существует решение по трансформации стен, используются приподнимающиеся раскладные кровати, убирающиеся в шкафы телевизоры, а мебель используется для хранения самых разных предметов.
Стены-трансформеры в небольшом помещении
Жилая площадь 35 кв. м
Визуальное расширение предусматривает некоторую перепланировку: снос перегородок и дверей, исключая туалет. Если есть балкон или лоджия, их можно утеплить, убрать часть стены и провести отопление. Получится удобный рабочий кабинет, детская комната или помещение для хранения вещей. Расширение квартиры за счет лоджии
Квартира 36 кв. м
Мелкие элементы интерьера можно подобрать потом, а основным стилем считается минимализм или хай-тек. Это простые и лаконичные формы, маленькая площадь занятости, универсальность и строгость линий. Для кухонной зоны мебель изготавливают на заказ, чтобы не терять ни сантиметра площади. В квартире останется еще много места для комфортного проживания. Зеркальные поверхности в минималистичном интерьере
Жилое пространство 38 кв. м
 м
мВ квартирах площадью 38 кв. м можно получить маленькую спальню и большую кухню или гостиную либо наоборот. Такой вариант больше подойдет для проживания одного человека или семьи без детей. Если есть балкон или лоджия, то их совмещение с кухней даст больше пространства, и можно сделать детскую комнату. При таком решении бытовую технику и рабочие поверхности размещают в районе лоджии, а столовую или гостиную зоны можно отделить барной стойкой. Зонирование барной стойкой
Площадь 39 кв. м
В таком дизайне часто используются раздвижные двери (скрытый пенал), значительно экономящие пространство. Ниши в стенах позволяют обустроить встроенные системы хранения. При наличии лоджии устанавливают мебель-трансформер для экономии места, то же самое делается и на кухне. Санузел обычно совмещенный, поэтому используется компактная мебель и сантехника. Вся электропроводка делается скрытой, для бытовой техники на кухне устанавливается отдельный электрощит. Раздвижные двери в интерьере однушки
Проект 40 кв. м
 м
мЧтобы помещение выглядело просторнее, все отдельные зоны необходимо связать друг с другом. Кухню объединяют с залом, в ванную комнату установлена прозрачная дверь, а спальное место отгорожено вертикальными полупрозрачными жалюзи. Здесь же можно поставить и детскую кроватку, оборудовать спальню для родителей. Расположение помещений в большой однокомнатной квартире
Студия для одного человека
Во всех однокомнатных квартирах, где общая и полезная площадь ограничена, рекомендуется изготавливать мебель на заказ. Нерациональное расположение типовой мебели лишь потратит ваши квадратные метры.
Даже при проживании одного человека лучше использовать мебель-трансформер, а лишнее пространство задействовать на свое усмотрение. Диван-трансформер в интерьере квартиры
Квартира для семейной пары
Светлые цвета и оттенки в дизайне помещений разрешают создать на маленькой площади полный комфорт, а также визуально увеличить пространство. В жилом помещении площадью в 20 м2 можно комфортно расположить многофункциональные зоны. Например, зону отдыха ночью трансформировать в спальню, а кресло-трансформер и книжный стеллаж – в рабочий уголок.
Полуперегородки в квартире
Жилье для семьи с одним ребенком
Даже при дефиците полезной площади дизайн 1-комнатной квартиры для пары с ребенком нужно организовать предельно комфортно. Спальная зона для родителей так же необходима, как и место для сна ребенка, поэтому следует добиться размещения двух отдельных спальных мест. Это можно сделать, установив не двуспальную кровать, а раскладной диван-трансформер, днем превращающийся в небольшую софу. Дизайн маленькой квартиры для семьи с одним ребенком – одна комната площадью 17 м2
Дизайн маленькой квартиры для семьи с одним ребенком – одна комната площадью 17 м2
Рекомендации по выбору стиля и функционала жилья
Наиболее эффективные рекомендации по созданию комфортного интерьера 1-комнатного жилья:
- Минимализм. Покупка многофункциональной мебели и предметов интерьера – главный прием для получения максимума пространства. Это может быть диван с выдвигающейся столешницей, складной стол и т.д. Такую мебель изготавливают на заказ.
- Ненавязчивый интерьер. Чтобы визуально расширить пространство, используют зеркальные или глянцевые поверхности, помещение зонируется легкими тканевыми или стеклянными перегородками. Также можно применять перегородки высотой до 1 м – главное, подобрать подходящий стройматериал. Полы в разных зонах также должны отличаться, например, плитка на кухне и линолеум в зале. В спальне уместным будет ковер или ковролин. В каждой зоне устанавливается отдельный электрический светильник, прокладка проводки – скрытая.
- Акцентирование и контраст. Один тон использовать не рекомендуется – лучше выделить пару-тройку главных и правильно распределить оттенки по поверхностям. Много темного цвета визуально сожмет пространство, светлые тона – расширят.
- Перепланировка. Внутренние перегородки (если они есть) в маленькой комнате уменьшают или вообще убирают, заменяя их перегородками в японском стиле – бумажными или тканевыми.
- Многофункциональная кладовая. В старых квартирах (сталинках, хрущевках) всегда строили кладовку, и ее можно использовать функционально. Например, в качестве встроенного шкафа или гардеробного помещения.
- Трехметровый потолок позволит разместить так называемую кровать-чердак, устанавливаемую на подиум. Под кроватью оборудуется шкаф для хранения вещей. Этот прием объединит два элемента мебели в один.
- Правильное использование элементов декора и текстиля. Не нагружайте маленькую квартиру небольшими предметами интерьера – игрушками, шкатулками, вазочками, статуэтками. На окна повесьте тканевые жалюзи или легкие полупрозрачные шторы, например, рулонного типа.
 На окна повесьте тканевые жалюзи или легкие полупрозрачные шторы, например, рулонного типа.
На окна повесьте тканевые жалюзи или легкие полупрозрачные шторы, например, рулонного типа.Как расставить мебель в помещении
Каждая зона в помещении имеет свое назначение, расположение дверей и окон, размеры и освещение. Поэтому рекомендуется придерживаться общепринятых правил расстановки мебели в каждой зоне:
- Предварительно стоит узнать размеры каждой зоны и мебели. Можно на миллиметровке расчертить площадь квартиры в выбранном масштабе. Затем вырезать из картона фигурки интерьера в верной пропорции и расставить их на чертеже.
- Для правильной организации пространства определяется главный элемент. В гостиной это может быть телевизор или шкаф. В спальне – кровать или диван, на кухне – стол.
- Расчетное расстояние между мебелью – 1,8-2,4 м.
- Углы в комнате заполняют не привлекающими внимание предметами.
- Между столом, стульями, диваном соблюдается расстояние 60-80 см.
- В помещении с двумя разнесенными окнами вешают зеркала, чтобы визуально увеличить пространство.
- Если помещение узкое и длинное, то нужна светлая компактная мебель. Окна рекомендуется завесить плотными шторами и пользоваться искусственным освещением. Полки и другие горизонтальные поверхности нельзя заставлять маленькими предметами и украшениями.
Draft2Digital представляет улучшенный автоматизированный макет для печати
Возможно, вы уже знаете, что автоматизированная верстка для печати является частью пакета, когда вы бесплатно конвертируете рукопись с помощью Draft2Digital. Теперь мы обновили интерфейс, чтобы дать вам больше вариантов размера макета и более четкое преобразование, чем раньше!
Теперь мы обновили интерфейс, чтобы дать вам больше вариантов размера макета и более четкое преобразование, чем раньше!
Мы вернули все на чертежную доску и разработали способ создания привлекательного печатного PDF-файла, который вы можете загрузить в CreateSpace, Lightning Source или в любую другую службу публикации по запросу.
В этом обновлении вы найдете:
- Улучшенное преобразование PDF
- Улучшенный конечный материал
- Теперь вы можете выбрать размер страницы в мягкой обложке
- Переносы включены
- Улучшено отображение гиперссылок и сносок
Плюс другие закулисные улучшения, которые сделают ваш макет максимально чистым и красивым!
Мы очень рады предложить авторам способ автоматизации макетов печати, устраняющий одну сложную, а иногда и дорогую часть накладных расходов.
Бесплатная верстка для любой операционной системы
Автоматизированный макет D2D для печати является бесплатным и основан на браузере, поэтому вы можете использовать его независимо от того, какую операционную систему вы предпочитаете. Если у вас уже есть учетная запись Draft2Digital, вы должны просто войти в систему, загрузить свою рукопись как документ Word (специального форматирования не требуется — просто используйте стиль «Заголовок 1» для заголовков глав) и получите бесплатное преобразование в EPUB, MOBI и готовый к печати PDF-файл. Вы даже можете выбрать подходящий размер.
Если у вас уже есть учетная запись Draft2Digital, вы должны просто войти в систему, загрузить свою рукопись как документ Word (специального форматирования не требуется — просто используйте стиль «Заголовок 1» для заголовков глав) и получите бесплатное преобразование в EPUB, MOBI и готовый к печати PDF-файл. Вы даже можете выбрать подходящий размер.
Когда у вас есть готовый к печати PDF-файл, вы можете загрузить его в любую службу POD, которую вы предпочитаете, включая CreateSpace и Lightning Source.
Вам не нужно использовать D2D для распространения ваших электронных книг, чтобы использовать этот бесплатный инструмент преобразования.Конечно, мы бы предпочли, чтобы это сделали вы!
Простая кнопка для макета печати
Это так просто! Начните автоматизировать печать макета книги, посетив панель управления Мои книги. Выберите свою книгу и на странице Подробная информация о книге выберите нужный размер обрезки, затем нажмите «Загрузить PDF».
Если у вас возникнут вопросы, обращайтесь в службу поддержки в любое время!
Удачной публикации!
Команда D2D
: общие сведения об автоматической компоновке
Общие сведения об автоматической компоновке
Auto Layout динамически вычисляет размер и положение всех представлений в вашей иерархии представлений на основе ограничений, наложенных на эти представления.Например, вы можете ограничить кнопку так, чтобы она располагалась по центру по горизонтали с видом изображения и чтобы верхний край кнопки всегда оставался на 8 пунктов ниже низа изображения. Если размер или положение изображения изменяется, положение кнопки автоматически изменяется.
Такой подход к проектированию, основанный на ограничениях, позволяет создавать пользовательские интерфейсы, которые динамически реагируют как на внутренние, так и на внешние изменения.
Внешние изменения
Внешние изменения происходят при изменении размера или формы вашего супервизора. С каждым изменением вы должны обновлять макет иерархии представлений, чтобы максимально использовать доступное пространство. Вот некоторые общие источники внешних изменений:
С каждым изменением вы должны обновлять макет иерархии представлений, чтобы максимально использовать доступное пространство. Вот некоторые общие источники внешних изменений:
Пользователь изменяет размер окна (OS X).
Пользователь входит или выходит из режима Split View на iPad (iOS).
Устройство вращается (iOS).
Полосы активных вызовов и аудиозаписи появляются или исчезают (iOS).
Вы хотите поддерживать классы разных размеров.
Вы хотите поддерживать разные размеры экрана.
Большинство этих изменений могут происходить во время выполнения и требуют динамического ответа от вашего приложения. Другие, например, поддержка разных размеров экрана, представляют приложение, адаптирующееся к разным средам. Даже несмотря на то, что размер экрана обычно не меняется во время выполнения, создание адаптивного интерфейса позволяет вашему приложению одинаково хорошо работать на iPhone 4S, iPhone 6 Plus или даже iPad. Автоматическая компоновка также является ключевым компонентом для поддержки слайд-просмотра и разделения представлений на iPad.
Автоматическая компоновка также является ключевым компонентом для поддержки слайд-просмотра и разделения представлений на iPad.
Внутренние изменения
Внутренние изменения происходят при изменении размера представлений или элементов управления в пользовательском интерфейсе.
Вот некоторые общие источники внутренних изменений:
Контент, отображаемый приложением, изменится.
Приложение поддерживает интернационализацию.
Приложение поддерживает динамический тип (iOS).
Когда содержимое вашего приложения изменяется, для нового содержимого может потребоваться другой макет, чем для старого.Обычно это происходит в приложениях, отображающих текст или изображения. Например, новостному приложению необходимо настроить макет в зависимости от размера отдельных новостных статей. Точно так же фотоколлаж должен обрабатывать широкий диапазон размеров изображений и соотношений сторон.
Интернационализация — это процесс адаптации вашего приложения к различным языкам, регионам и культурам. Макет интернационализированного приложения должен учитывать эти различия и правильно отображаться на всех языках и регионах, которые поддерживает приложение.
Интернационализация оказывает на макет три основных эффекта. Во-первых, когда вы переводите свой пользовательский интерфейс на другой язык, метки требуют другого места. Например, для немецкого языка обычно требуется значительно больше места, чем для английского. Японцы часто требуют гораздо меньше.
Во-вторых, формат, используемый для представления дат и чисел, может меняться от региона к региону, даже если язык не меняется. Хотя эти изменения обычно более тонкие, чем изменения языка, пользовательский интерфейс все же должен адаптироваться к небольшому изменению размера.
В-третьих, изменение языка может повлиять не только на размер текста, но и на организацию макета. На разных языках используются разные направления макета. Например, для английского языка используется направление компоновки слева направо, а для арабского и иврита — направление компоновки справа налево. В целом порядок элементов пользовательского интерфейса должен соответствовать направлению макета. Если кнопка находится в правом нижнем углу представления на английском языке, она должна быть в левом нижнем углу на арабском языке.
Например, для английского языка используется направление компоновки слева направо, а для арабского и иврита — направление компоновки справа налево. В целом порядок элементов пользовательского интерфейса должен соответствовать направлению макета. Если кнопка находится в правом нижнем углу представления на английском языке, она должна быть в левом нижнем углу на арабском языке.
Наконец, если ваше приложение iOS поддерживает динамический тип, пользователь может изменить размер шрифта, используемый в вашем приложении. Это может изменить как высоту, так и ширину любых текстовых элементов в вашем пользовательском интерфейсе. Если пользователь изменяет размер шрифта во время работы вашего приложения, шрифты и макет должны адаптироваться.
Автоматическая компоновка по сравнению с компоновкой на основе кадров
Существует три основных подхода к созданию пользовательского интерфейса. Вы можете программно разметить пользовательский интерфейс, вы можете использовать маски автоизменения размеров для автоматизации некоторых реакций на внешние изменения, или вы можете использовать Auto Layout.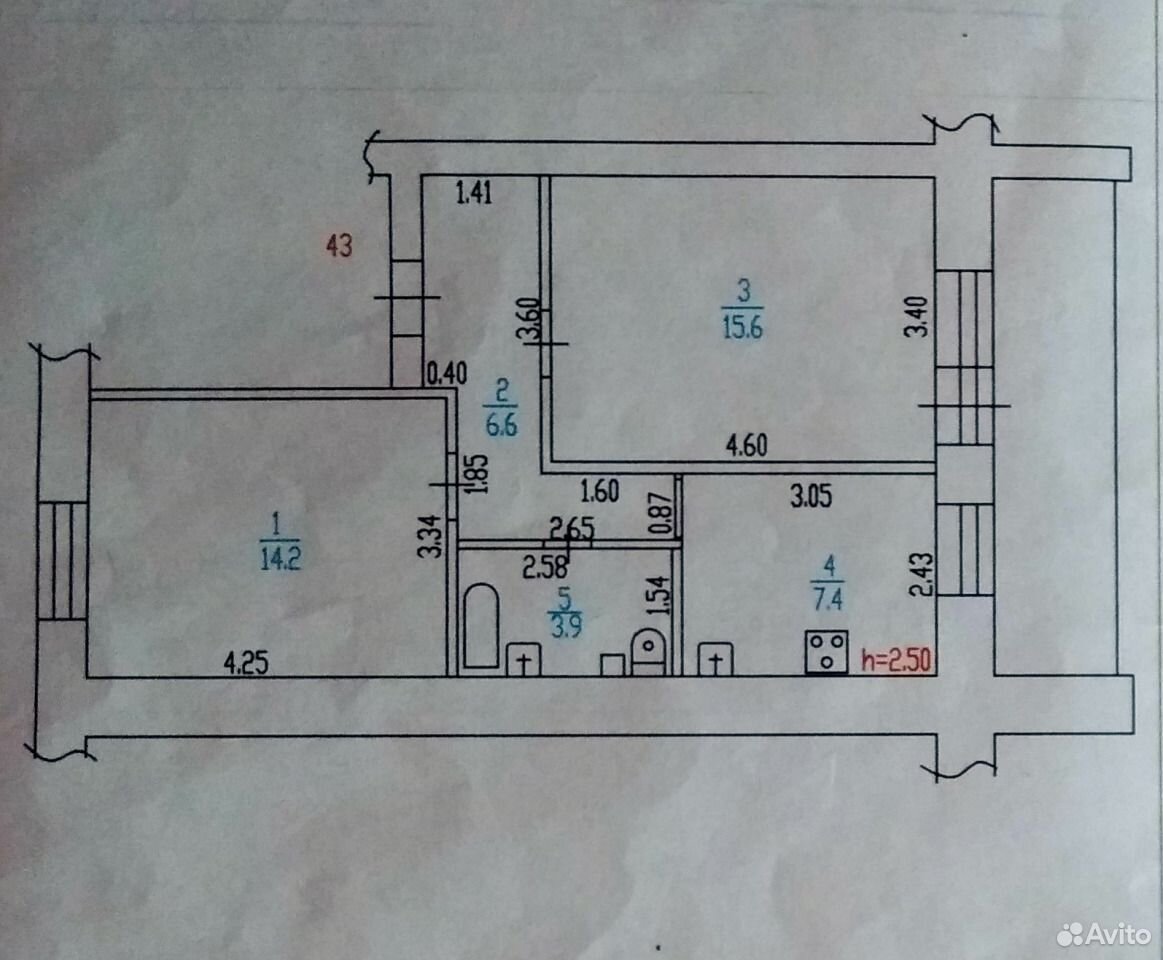
Традиционно приложения формируют свой пользовательский интерфейс, программно устанавливая фрейм для каждого представления в иерархии представлений. Фрейм определяет исходную точку, высоту и ширину представления в системе координат супервизора.
Чтобы создать свой пользовательский интерфейс, вам нужно было рассчитать размер и положение для каждого представления в иерархии представлений. Затем, если происходило изменение, вам приходилось пересчитывать кадр для всех затронутых видов.
Во многих отношениях программное определение кадра представления обеспечивает максимальную гибкость и мощность.Когда происходит изменение, вы можете внести любое изменение, которое захотите. Тем не менее, поскольку вы также должны самостоятельно управлять всеми изменениями, создание простого пользовательского интерфейса требует значительных усилий для разработки, отладки и поддержки. Создание действительно адаптивного пользовательского интерфейса увеличивает сложность на порядок.
Вы можете использовать маски с автоизменением размеров, чтобы облегчить некоторые из этих усилий. Маска с автоизменением размера определяет, как изменяется рамка представления при изменении рамки суперпредставления.Это упрощает создание макетов, адаптированных к внешним изменениям.
Однако маски с автоизменением размеров поддерживают относительно небольшое подмножество возможных макетов. Для сложных пользовательских интерфейсов вам обычно необходимо дополнить маски автоизменения размеров вашими собственными программными изменениями. Кроме того, маски с автоизменением размеров адаптируются только к внешним изменениям. Они не поддерживают внутренние изменения.
Хотя автоизменение размеров масок — это всего лишь итеративное улучшение программных макетов, Auto Layout представляет собой совершенно новую парадигму.Вместо того чтобы думать о фрейме представления, вы думаете о его отношениях.
Auto Layout определяет ваш пользовательский интерфейс с помощью ряда ограничений. Ограничения обычно представляют собой отношения между двумя представлениями. Затем Auto Layout вычисляет размер и расположение каждого вида на основе этих ограничений. Это создает макеты, которые динамически реагируют как на внутренние, так и на внешние изменения.
Ограничения обычно представляют собой отношения между двумя представлениями. Затем Auto Layout вычисляет размер и расположение каждого вида на основе этих ограничений. Это создает макеты, которые динамически реагируют как на внутренние, так и на внешние изменения.
Логика, используемая для разработки набора ограничений для создания определенного поведения, очень отличается от логики, используемой для написания процедурного или объектно-ориентированного кода.К счастью, освоение Auto Layout ничем не отличается от освоения любой другой задачи программирования. Есть два основных шага: сначала вам нужно понять логику макетов на основе ограничений, а затем вам нужно изучить API. Вы успешно выполнили эти шаги при изучении других задач программирования. Auto Layout — не исключение.
Остальная часть этого руководства предназначена для облегчения перехода на автоматический макет. Глава Auto Layout Without Constraints описывает высокоуровневую абстракцию, которая упрощает создание пользовательских интерфейсов, поддерживаемых Auto Layout. В главе «Анатомия ограничения» представлена основная теория, которую вам необходимо понять, чтобы самостоятельно успешно взаимодействовать с Auto Layout. Работа с ограничениями в Интерфейсном Разработчике описывает инструменты для разработки Auto Layout, а главы Программного создания ограничений и Auto Layout Cookbook подробно описывают API. Наконец, «Поваренная книга автоматического макета» представляет широкий спектр примеров макетов разного уровня сложности, которые вы можете изучать и использовать в своих собственных проектах, а «Отладка автоматического макета» предлагает советы и инструменты для исправления ошибок, если что-то пойдет не так.
В главе «Анатомия ограничения» представлена основная теория, которую вам необходимо понять, чтобы самостоятельно успешно взаимодействовать с Auto Layout. Работа с ограничениями в Интерфейсном Разработчике описывает инструменты для разработки Auto Layout, а главы Программного создания ограничений и Auto Layout Cookbook подробно описывают API. Наконец, «Поваренная книга автоматического макета» представляет широкий спектр примеров макетов разного уровня сложности, которые вы можете изучать и использовать в своих собственных проектах, а «Отладка автоматического макета» предлагает советы и инструменты для исправления ошибок, если что-то пойдет не так.
Автоматическая компоновка без ограничений
© Apple Inc., 2018. Все права защищены. Условия использования | Политика конфиденциальности | Обновлено: 21.03.2016
идей — OpenCog
См. Страницу Начало 2017 г. Ideas_Page
См. Также шаблон StudentApplicationTemplate, Разработка. OpenCog через Википедию и публикации для фонового чтения. Обратите внимание, что мы приветствуем всех заинтересованных волонтеров для работы над этими проектами, а не только соискателей GSoC!
Обратите внимание, что мы приветствуем всех заинтересованных волонтеров для работы над этими проектами, а не только соискателей GSoC!
Остальная часть этой страницы описывает многие проектные идеи для дальнейшего развития OpenCog и связанных проектов.Это своего рода беспорядок — например, некоторые из проектов уже выполнены …. Но материал пока что здесь, потому что кое-где есть полезные части; он будет убран «скоро» ….
Большинству проектов здесь присвоены метки сложности:
- Относительно простые исследования и разработки в области ИИ, хотя и непростые
- Довольно сложно
- Довольно сложно
Обратите внимание, что эти метки относятся только к аспектам AI задачи; также могут быть сложные аспекты разработки программного обеспечения или системной интеграции, которые не были обозначены.Лучше всего спросить нас напрямую, если вас беспокоит потенциальная проблема, которую представляет проект.
OpenCog состоит из базовой структуры с несколькими модулями. В этом разделе описаны проекты, связанные с улучшением фреймворка, который поддерживает остальные модули и MindAgents, построенные на нем. Если не указано иное, эти проекты не требуют передовых знаний, связанных с ИИ.
В этом разделе описаны проекты, связанные с улучшением фреймворка, который поддерживает остальные модули и MindAgents, построенные на нем. Если не указано иное, эти проекты не требуют передовых знаний, связанных с ИИ.
Упаковка для Debian, Cygwin, OS X
Упаковка таких компонентов OpenCog, как CogServer и Embodiment для популярных операционных систем, может помочь расширить наши сообщества пользователей и разработчиков.
В настоящее время OpenCog компилируется для Linux и не упакован для какой-либо ОС. Проект переноса и упаковки будет включать работу со спецификациями файлов CMake, компилятора gcc, компоновщика и загрузчика общих объектов, а также с инструментами упаковки для Debian / Ubuntu, Cygwin или MinGW и OS X (пакеты установщика .pkg, порты или homebrew).
Требования и шаги проекта см. В разделе «Упаковка».
Перенос OpenCog на Windows
Cygwin, вероятно, самый простой способ портировать кодовую базу OpenCog в Windows.Но у платформы Windows есть и недостатки, главный из которых — потеря скорости. Неясно, пострадает ли OpenCog от этого, поскольку большая часть его ресурсов тратится на научные вычисления, а не на системные вызовы, но в случае, если версия Cygwin действительно медленнее, чем должна быть, стоит подумать о переносе Windows. Но это сработает только в среднесрочной / долгосрочной перспективе, если кто-то всегда желает поддерживать совместимость с течением времени. Учитывая, что OpenCog находится в активной разработке, в противном случае он быстро устарел бы.
Неясно, пострадает ли OpenCog от этого, поскольку большая часть его ресурсов тратится на научные вычисления, а не на системные вызовы, но в случае, если версия Cygwin действительно медленнее, чем должна быть, стоит подумать о переносе Windows. Но это сработает только в среднесрочной / долгосрочной перспективе, если кто-то всегда желает поддерживать совместимость с течением времени. Учитывая, что OpenCog находится в активной разработке, в противном случае он быстро устарел бы.
Распределенная и постоянная производительность AtomSpace
Обеспечение распределенных рабочих нагрузок и тестов AtomSpace с сохранением и синхронизацией.
Задачи включают:
- Получение «типовой» рабочей нагрузки, чтобы можно было понять производительность.
- Разработка сценариев для запуска этой рабочей нагрузки в нескольких системах, загружаемых с помощью контейнеров Vagrant.
- Расширение существующего эталонного теста, чтобы иметь возможность запускать эту рабочую нагрузку и измерять производительность.
- Выполните фактические контрольные измерения на существующей серверной части.
- Возможно расширение существующей серверной части для поддержки дополнительных индексов, которые могут потребоваться для рабочей нагрузки.
- Возможно создание нового серверного интерфейса для другой системы баз данных.

Текущая лучшая идея для этого отслеживается в выпуске github # 1502. Для этого сначала необходимо удалить большинство случаев использования SetLink и заменить его на MemberLink. Затем атом можно сделать принадлежащим пространству атомов, используя новую ссылку AtomSpaceLink.Это устраняет большую часть сложности реализации, открывая дверь в порт атомного пространства для Apache Ignite, который в настоящее время кажется лучшим выбором для распределенной платформы.
Когнитивный API
Разработать и внедрить начальную структуру для когнитивного API, который можно масштабировать, чтобы удовлетворить высокоуровневый обзор, описанный @ http://wiki. opencog.org/w/A_Cognitive_API
opencog.org/w/A_Cognitive_API
Улучшенная компоновка для визуализатора AtomSpace
Скотт Джонс написал хороший визуализатор AtomSpace, работающий в сети и взаимодействующий с AtomSpace через REST API.Однако макеты графов, предоставляемые визуализатором Atomspace, часто неоптимальны с учетом топологии подграфов AtomSpace. Например, когда визуализируемый подграф является древовидным, было бы хорошо использовать древовидный менеджер компоновки.
- Хорошо подходит для семестра кода; Бен или Космо могли бы стать наставником
OpenCog Visualization Workbench
Визуализатор AtomSpace обращается только к одному аспекту пользовательского интерфейса для понимания динамики OpenCog. Было бы полезно использовать универсальную рабочую среду с графическим пользовательским интерфейсом, которая может обрабатывать синтаксический анализ файлов журнала и динамическую настройку работающего экземпляра OpenCog.
Другие особенности, которыми может обладать такой верстак:
- график динамики во времени:
- всего атомов различных типов
- Распределение истинностных значений
- Распределение важности атомов (STI / LTI)
- среднее координационное число (число звеньев, с которыми связаны атомы)
- диаметр сети
- Количество непересекающихся кластеров
- визуализирует и контролирует расширение дерева обратного вывода PLN.
- активных агентов MindAgents и их использование ресурсов (память, ЦП)

Это также может быть интегрировано или сделано для включения функций графического интерфейса OpenPsi, разработанного Чжэньхуа Цай. Этот интерфейс использует:
- сообщений zeromq для отслеживания изменений состояния из OpenCog.
- на Python.
- pyqt для виджетов.
- Хорошо подходит для семестра кода; Бен или Космо могут быть наставником
Пользовательские индексы
AtomSpace — это, по сути, своего рода графическая база данных.Как и другие базы данных, он должен позволять пользователям определять типы структур, которые им необходимо быстро находить. Это можно сделать с помощью определяемого пользователем индекса; индекс будет поддерживаться путем запуска сопоставителя шаблонов для вновь созданных конфигураций атомов.
Это требует выполнения работы в сочетании с предложением по проверке типа, приведенным выше.
Полезность: У нас была возможность делать это уже десять лет, но за последние 10 лет этого никто не хотел. Это вообще кому интересно?
Это вообще кому интересно?
Сложность: в основном прямолинейное кодирование, исследования ИИ практически не требуются. Сложнее всего будет понять существующую кодовую базу, чтобы понять, где и как это разместить.
- Хорошо подходит для семестра кода; вероятно, Линас мог бы наставником
Проверка типов
В настоящее время в Atomspace ничто не мешает вам создавать
InheritanceLink NumberNode "9" GoundedSchemaNode "печать"
хоть это ерунда….
В AtomSpace проверка типов необходима, чтобы пользователи не добавляли несоответствующие атомы в атомное пространство. Это также жизненно важная часть возможности предоставлять определяемые пользователем индексы. (Смотри ниже). Подсистема типов уже достаточно богата, чтобы полностью описывать типы атомов; он просто не настроен на мониторинг создания конкретных атомов. Не то, чтобы у некоторых / многих типов атомов есть классы C ++, у которых есть конструкторы, которые проверяют структуру атома. В приведенном выше примере нетрудно создать класс InheritanceLink для выполнения этой проверки.
Полезность : Это действительно полезно? Это повсюду влияет на производительность, и важные классы, например BindLink, уже сделай это.
Сложность: в основном прямолинейное кодирование, исследования ИИ практически не требуются. Сложнее всего будет понять существующую кодовую базу, чтобы понять, где и как это разместить.
- Хорошо подходит для семестра кода; вероятно, Линас мог бы стать наставником
Проверка типов за
злотыхArrowLink — это конструктор функционального типа, позволяющий указывать тип A-> B, где A-> B означает функцию, принимающую A в качестве ввода и возвращающую B.Например, функция, принимающая число в качестве входных данных и концепт в качестве выходных данных, может быть записана как
ArrowLink
TypeNode "NumberNode"
TypeNode "ConceptNode"
TypedAtomLink можно использовать для связывания указанной выше сигнатуры функции с конкретным атомом; например:
TypedAtomLink
SchemaNode "схема foobar"
ArrowLink
TypeNode "NumberNode"
TypeNode "ConceptNode"
Выше указано, что схема «foobar schema» — это функция, которая принимает число в качестве входных данных и возвращает концепцию в качестве выходных данных.
Прямо сейчас ограничения типов неявны в пространстве Atomspace, что в целом нормально, поскольку в данный момент мы в основном имеем дело с простыми случаями.
Однако, чтобы расширить PLN, создание концепций и другие функции для эффективной работы с типами высшего порядка, вероятно, потребуется явная типизация. Это будет полезно для абстрактных рассуждений, не только математических рассуждений, но, например, для аналогичных рассуждений между существенно разными областями или экспериментального изучения основ символов или лингвистических правил.
См. Также идею «проверки типов» выше.
Метаоптимизирующий семантический эволюционный поиск (MOSES) — это новый подход к эволюции программ, основанный на построении представлений и вероятностном моделировании. MOSES успешно применялся для решения сложных задач в таких областях, как вычислительная биология, оценка настроений и контроль агентов. Результаты имеют тенденцию быть более точными и требуют меньшего количества оценок целевой функции по сравнению с другими системами развития программы. Лучше всего то, что результатом работы MOSES является не большая вложенная структура или числовой вектор, а компактная и понятная программа, написанная на простом Lisp-подобном мини-языке. Подробнее на MOSES.
Лучше всего то, что результатом работы MOSES является не большая вложенная структура или числовой вектор, а компактная и понятная программа, написанная на простом Lisp-подобном мини-языке. Подробнее на MOSES.
См. Также страницу идей MOSES. Содержимое всего этого раздела нужно переместить туда … и очистить, расширить.
Добавить поддержку временного ряда
Прямо сейчас MOSES вообще не поддерживает временные ряды.
Это важно для вывода дифференциальных уравнений (из конечных разностей), которые являются центральными для обучения движению и движению, что, в свою очередь, является центральным для движения роботов и занятий спортом (мяч летит на вас; вы видите это в своем видео).Где должен быть ваш робот-захват, чтобы его поймать? Когда должен закрываться захват? Мяч искривляется из-за силы тяжести, и, возможно, это нервный шар и замедление из-за сопротивления воздуха, поэтому вам нужны две соседние точки временного ряда, чтобы найти разностное уравнение 2-го порядка. )
)
Так, например, из видеопотока у вас есть положение шара x, y в моменты времени t1, t2, t3 …
Сейчас moses принимает в качестве входных данных набор строк; эти строки могут быть в любом порядке; они не связаны друг с другом.Конечно, вы могли бы дать ему строки:
t1, x1, y1 t2, x2, y2 t3, x3, y3
, и, возможно, он мог бы что-то сделать, но это гораздо более сложная проблема, потому что это интегральная проблема, а не дифференциальная проблема. Вы хотите увидеть различия между соседними строками, а сейчас MOSES не может этого сделать. Найти разностные уравнения гораздо проще, чем интегральные.
Вы можете обойти это разными уродливыми способами, например складывать два-три ряда в один, но это так.. хаки. например
т1 х1 у1 х2 у2 t2 x2 y3 x3 y3 t3 x3 y3 x4 y4
фу.
Создайте аналог OpenBiomind с помощью MOSES
OpenBiomind — это набор инструментов Java, содержащий код для применения генетического программирования для анализа данных микрочипа экспрессии генов и данных SNP. Этот подход успешно использовался для изучения правил диагностики рака, болезни Альцгеймера, Паркинсона и других заболеваний, что отражено в нескольких публикациях.
Этот подход успешно использовался для изучения правил диагностики рака, болезни Альцгеймера, Паркинсона и других заболеваний, что отражено в нескольких публикациях.
MOSES — более мощный инструмент для анализа данных микрочипов и SNP, чем система GP, используемая в OpenBiomind.Кроме того, код Java для OpenBiomind не такой гибкий и расширяемый, как должен быть.
Хотелось бы реализовать аналог OpenBiomind на MOSES. В этом направлении уже достигнут большой прогресс с использованием языка R, но еще предстоит реализовать другие части.
- Хорошо подходит для семестра кода; Майк Дункан может быть наставником
Использование методов ядра для предварительной фильтрации непрерывных данных
Данные с непрерывными значениями часто очень зашумлены, и поэтому их трудно подобрать (т.е. трудно сходиться к хорошо подходящей функции). Можно удалить (отфильтровать) большую часть шума, разделив его на дискретные ячейки; и замену признака с непрерывным знаком дискретным значением (или как N признаков с двоичным значением для некоторого малого N).
Проблема с биннингом состоит в том, что при наличии нескольких объектов с непрерывным значением они часто сильно коррелированы друг с другом. Их объединение в несколько погашает эту корреляцию, что, вероятно, не очень хорошо. Таким образом, было бы лучше, если бы свойства с непрерывным знаком были диагонализованы в ортогональные компоненты перед группированием.Алгоритмы SVM, PCA и перцептрона — хорошие способы выполнить эту диагонализацию. Все они реализуют общую, базовую идею диагонализации, называемую «методами ядра».
Итак: идея состоит в том, чтобы передать непрерывнозначные функции через этап диагонализации, прежде чем передавать их в MOSES. Примечание: для этого необходимо найти хороший набор данных, который продемонстрирует полезность этого подхода.
Включите MOSES для изучения рекурсивных функций с помощью свертки
В Reduct / MOSES используйте алгебру свертки, как намекает Моше внизу страницы 5 «Представления программ для обучения и рассуждений» (Looks, Goertzel).
Combo в настоящее время поддерживает примитив свертки и списки. Однако в настоящее время нет четкого / практического способа их развертывания в контексте MOSES.
Итак, что нужно сделать, это
- разработать способ представления рекурсивных данных в MOSES
- правил проектирования и сокращения кода для этой новой программной конструкции,
- обновляет здание представления, чтобы MOSES мог развивать программы с помощью списков и сворачивания.
- протестируйте это на некоторых подходящих тестовых примерах,
Один подходящий тестовый пример может изучать процедуру сортировки nlogn
Например, сортировка слиянием может быть реализована в Haskell как
mergesort xs = foldt merge [] [[x] | x <- xs]
с функцией merge - вариант объединения с сохранением дубликатов.
XXX: Мне непонятно, как мы вообще представляем данные списка в МОИСЕЙ. Мне не ясно, где такие данные возникают естественным образом. Я не знаю никаких роботизированных датчиков, финансовых данных, биологических данных или текстовых / nlp-алгоритмов, которые естественным образом создают списки данных. Итак, даже если бы у нас была эта функция, где бы она была применена? Как это применить?
Я не знаю никаких роботизированных датчиков, финансовых данных, биологических данных или текстовых / nlp-алгоритмов, которые естественным образом создают списки данных. Итак, даже если бы у нас была эта функция, где бы она была применена? Как это применить?
XXX Учитывая список, какую рекурсивную обработку мы хотели бы выполнить с ним (помимо сортировки списка)? Или, скорее, какой рекурсивной структурой могут обладать некоторые входные данные, чтобы нам пришлось их автоматически изучать? Напомним, цель МОИСЕЯ - найти скрытые, необнаруженные, неизвестные закономерности.Какие примитивные рекурсивные шаблоны мы можем ожидать найти? Найдя их, что мы будем с ними делать?
Сложность: 1-2-3
Ссылки:
Обобщить сокращение и представление, построенное на свойствах оператора
Одна проблема как с Reduct, так и с построением представления заключается в том, что они в значительной степени жестко привязаны к набору операторов и, или нет, +, * и т. Д. Хотя нам бы хотелось, чтобы они вместо этого полагались на свойства операторов ( я. е. в смысле теории категорий, теории моделей).
е. в смысле теории категорий, теории моделей).
Например, вместо правила
х + 0 -> х
а также правило
x или ложь -> x
у нас может быть одно правило
x OP NE -> x
где NE - единичный элемент оператора OP.
XXX - действительно ли достаточно примеров этого в комбинации, чтобы оправдать эту работу? Так, например, у нас есть:
- элемент единицы: x + 0 -> x, x или F -> x, x и T = x
- общий закон о распределении
- общий ассоциативный закон
- общий коммутативный закон
- общее деление (??)
Но мы уже реализовали это для логических и непрерывных (непрерывных) переменных; неясно, есть ли большая польза от этого в целом, поскольку в настоящее время у нас нет планов использовать Моисей для изучения групп, идеалов, колец, целочисленных областей, модулей, векторных пространств, магм, категорий, эллиптических кривых, моноидов, схем , пучки, пучки волокон, гомологии и т. д., где эти абстрактные теоретико-категориальные концепции действительно полезны и важны.
д., где эти абстрактные теоретико-категориальные концепции действительно полезны и важны.
XXX Кроме того, без работы, которая делает combo / reduct расширяемым (см. Предложение выше), эта работа не была бы очень полезной, поскольку в настоящее время нет практического способа добавления новых операторов в систему.
Эту же идею можно применить и к зданию представительства, хотя и посложнее. Очевидным преимуществом этого является то, что когда нужно расширить сокращение с помощью новых операторов, нет необходимости добавлять новые правила сокращения (если оператор не включает новые свойства), достаточно установить свойства оператора, и мы сделанный.
Говоря более абстрактно: добавить поддержку алгебраических структур и их интерпретаций в смысле теории моделей. То, что выше называется «оператором», на самом деле является «алгебраической структурой», а «x + 0 -> x» и «x или F -> x» - это две разные «интерпретации» этой структуры. Такие системы называются «теориями»; пример, где эта абстракция уже используется, - в решателях SMT (Satisfiability Modulo Theories). Статья в Википедии о SMT дает список «теорий», которые может поддержать MOSES.
Статья в Википедии о SMT дает список «теорий», которые может поддержать MOSES.
Другие обсуждения см. В этой переписке.
Сложность: 2 для редукта, 3 для представительского здания
Программные конструкции высшего порядка
Важным проектом, подходящим для студента с некоторым опытом функционального программирования, является расширение MOSES для обработки программных конструкций более высокого порядка, включая выражения переменных.
Наш дизайн для этого включает в себя формализм Синота «управляющие струны как комбинаторы», и есть возможность помочь с проработкой деталей дизайна, а также с реализацией.Это можно сделать разными способами, в том числе с использованием комбинаторной логики или лямбда-исчисления. На данный момент лучшим вариантом будет использование формализма Синота о «управляющих строках как комбинаторах». Большая часть работы здесь находится в сокращении и построении репрезентации, что будет полезно как для MOSES, так и для Pleasure.
Сложность: 2
- Хорошо подходит для семестра кода; Нил мог быть наставником
Библиотека известных программ
В настоящее время MOSES конструирует программы из очень минимального набора функций и операторов; например, логические выражения полностью состоят из и , или , не .Однако изучение программ могло бы происходить намного быстрее, если бы были предоставлены более сложные примитивы: например, xor , полусумматор, мультиплексор, и т. Д. Вместо того, чтобы жестко запрограммировать такие функции в комбо, этот проект призывает универсальная библиотека, которая может содержать такие функции, и инфраструктура, позволяющая MOSES брать образцы из библиотеки при создании образцов.
Это необходимый шаг на пути к реализации приведенного ниже алгоритма удовольствие , а также для передачи обучения, и т. Д.
Это может быть выполнено летом, хотя для этого все равно потребуется очень сильный
программист. Доказательством того, что он работает, будет определение xor в некоторых
файл (как комбинированный, , а именно , что xor ($ 1, $ 2): = and (или ($ 1, $ 2), а не (и ($ 1, $ 2))) , а затем показать, что это определение действительно использовалось при решении задачи k-четности.
Доказательством того, что он работает, будет определение xor в некоторых
файл (как комбинированный, , а именно , что xor ($ 1, $ 2): = and (или ($ 1, $ 2), а не (и ($ 1, $ 2))) , а затем показать, что это определение действительно использовалось при решении задачи k-четности.
- Хорошо подходит для семестра кода; Нил мог быть наставником
Удовольствие
Завершить реализацию (или начать новую с нуля), а затем протестировать и изучить Алгоритм удовольствия для обучения программ, начатый в 2011 году Алесисом Новиком.Видеть МОИСЕЙ: алгоритм удовольствия
Предварительные требования: Библиотека известных подпрограмм , см. Выше.
Сложность: 3
Передача обучения
Заставляет MOSES обобщать экземпляры проблемы, чтобы то, что он узнал по множеству экземпляров проблемы, можно было использовать для помощи в обучении новым экземплярам проблемы. Это можно сделать, расширив этап построения вероятностной модели на несколько поколений, но это создает ряд дополнительных проблем и требует интеграции какого-то сложного метода распределения внимания в MOSES, чтобы сообщить ему, какие паттерны наблюдались в каких предыдущих проблемных случаях обрати внимание на.
Гораздо более простой подход - обменять потребности внутреннего цикла MOSES с внешним циклом. К сожалению, это был бы серьезный разрыв кодовой базы. Изменение порядка циклов позволило бы MOSES непрерывно обрабатывать бесконечное количество новых стимулов, по сути выполняя непрерывное непрерывное обучение с передачей. Это должно контрастировать с текущим дизайном: входные данные представляют собой таблицу фиксированного размера с фиксированным содержимым, и во время обучения она повторяется снова и снова во внутреннем цикле.Если бы порядок циклов был изменен на противоположный, то эквивалентную функцию можно было бы получить, просто воспроизводя один и тот же ввод до бесконечности. Однако теперь будет возможность НЕ воспроизводить один и тот же ввод снова и снова, а, скорее, он может медленно мутировать, и изученные структуры будут мутировать вместе с ним. Это гораздо более феноменологический, биологически правильный подход к обучению на основе входных стимулов.
Сложность: 2-3
Изучение произвольно сложной программы
Подробнее о предыдущем предложении по проекту: Мотивация для вышеизложенного - позволить MOSES изучать произвольно сложные программы. Например, мы хотели бы, чтобы он мог легко изучать алгоритмы сортировки nlogn без какой-либо сложной подготовки данных или другого «мошенничества». Возможно, интеграция формализма Синота в MOSES позволит эффективно изучать умеренно сложные программы с использованием рекурсивного управления, чего еще никто не достиг и что имеет решающее значение для автоматического обучения программ.
Например, мы хотели бы, чтобы он мог легко изучать алгоритмы сортировки nlogn без какой-либо сложной подготовки данных или другого «мошенничества». Возможно, интеграция формализма Синота в MOSES позволит эффективно изучать умеренно сложные программы с использованием рекурсивного управления, чего еще никто не достиг и что имеет решающее значение для автоматического обучения программ.
Предварительные требования: Библиотека известных подпрограмм , см. Выше.
Сложность: 3
Обработка последовательностей действий
Текущая версия MOSES не изящно и неэффективно обрабатывает обучение программ, включающих длинные последовательности действий.Это проблематично для приложений, связанных с управлением роботами или виртуальными агентами. Таким образом, важным проектом является расширение компонентов Reduct и построения представлений MOSES для эффективной обработки последовательностей действий. Эту работу можно будет протестировать с помощью MOSES для управления агентами в виртуальных мирах, таких как Multiverse или Unity.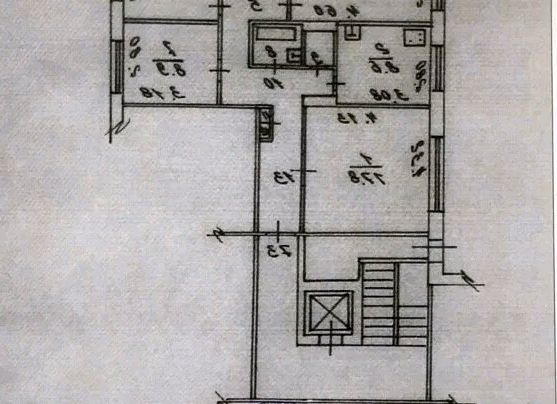
Использовать SVM для выбора дерева программ
Попробуйте заменить моделирование байесовой сетью в MOSES на SVM. SVM с ядрами дерева теперь несколько повзрослела, см. E.г.
http://www.xialuo.net/2010/11/07/svm-light-tk-1-2/
Итак, идея примерно такова:
- используют SVM, чтобы изучить модель, позволяющую отличать подходящие деревья от неподходящих программ.
- использует эту модель в качестве фильтра для сгенерированных программных деревьев, чтобы определить
, какие из них заслуживают оценки пригодности.
Сложность: 2
Улучшенный hBOA
MOSES состоит из четырех критических аспектов: управление демами, сокращение дерева программ, построение представлений и моделирование популяции.Для последнего в настоящее время используется алгоритм hBOA (изобретенный Мартином Пеликаном в его докторской диссертации 2002 г.), но мы обнаружили, что он не является оптимальным в этом контексте. Так что есть место для экспериментов по замене hBOA другим алгоритмом; например, был предложен вариант имитации отжига, а также подход распознавания образов, подобный сжатию LZ. Студент, знакомый с эволюционным обучением, теорией вероятностей и машинным обучением, может с удовольствием экспериментировать с альтернативами hBOA, чтобы помочь превратить MOSES в суперэффективную среду автоматизированного обучения программ.Он уже работает достаточно хорошо, значительно превосходя GP, но мы считаем, что, уделив некоторое внимание улучшению компонента hBOA, его можно значительно улучшить.
Студент, знакомый с эволюционным обучением, теорией вероятностей и машинным обучением, может с удовольствием экспериментировать с альтернативами hBOA, чтобы помочь превратить MOSES в суперэффективную среду автоматизированного обучения программ.Он уже работает достаточно хорошо, значительно превосходя GP, но мы считаем, что, уделив некоторое внимание улучшению компонента hBOA, его можно значительно улучшить.
- Хорошо подходит для семестра кода; Нил или Линас могут быть наставниками
Встраивание измерений для улучшения обучения программ
Предположим, что кто-то использует MOSES (или какой-либо связанный метод) для изучения программного дерева, которое содержит узлы, относящиеся к семантическим знаниям в большой базе знаний (например, дерево программы, которое содержит такие термины, как «кошка», «прогулка» и т. Д.которые представляют концепции в OpenCog AtomTable).
Затем, изменение этих узлов (для «построения представления» на жаргоне MOSES) требует некоторого специального механизма - например, кто-то хочет видоизменить «кот» в «какое-то другое понятие, полученное из гауссиана с заданной дисперсией, центрированного вокруг "кота" ".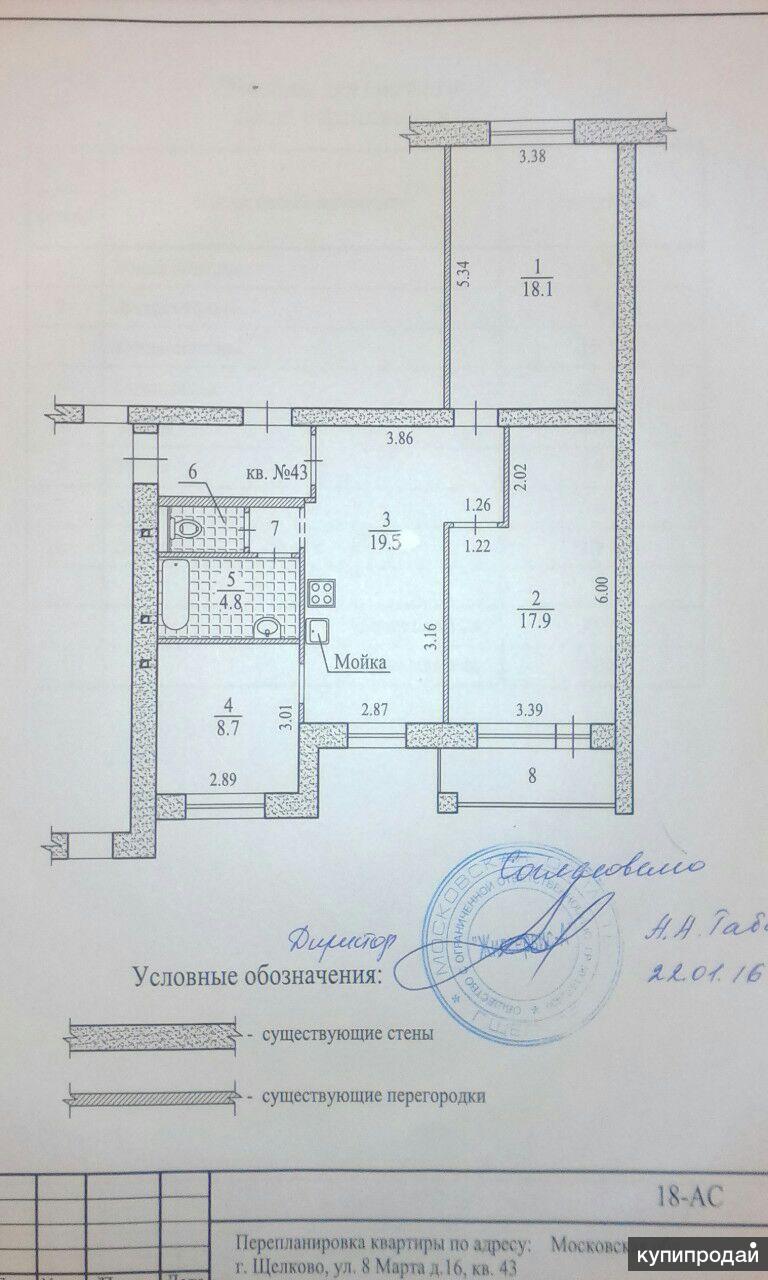 Один из простых способов сделать это - встроить концепции в семантическую базу знаний в n-мерное пространство, а затем использовать гауссовские распределения в этом размерном пространстве для мутации.
Один из простых способов сделать это - встроить концепции в семантическую базу знаний в n-мерное пространство, а затем использовать гауссовские распределения в этом размерном пространстве для мутации.
Мы определили несколько хороших алгоритмов для пространственного встраивания, но кодирование должно быть выполнено, и, вероятно, потребуется куча возни!
MOSES Эволюция рекуррентных нейронных сетей
В 2009 году Джоэл Леман работал над расширением MOSES для развития рекуррентных нейронных сетей. Он проделал отличную работу, но из-за ограниченных возможностей MOSES в работе с непрерывными ручками он не мог полностью экспериментировать со своей работой. Непрерывные ручки теперь полностью поддерживаются, но производительность эволюционного обучения NN показала лишь небольшой рост и в настоящее время не превосходит другие, более классические подходы.Мы не знаем почему, это может быть ошибка в коде, ошибка дизайна или что-то более фундаментальное.
Итак, цель этого проекта - продолжить работу Джоэла Лемана, сначала попытаться понять низкую производительность и исправить / улучшить ее, а затем, если позволяет время, реализовать и поэкспериментировать с другими классами RNN.
- Язык: продвинутый C ++
- Код: подлежит уточнению
- Список: подлежит уточнению
- Лицензия: TBD
Вероятностные логические сети (PLN) - это новый концептуальный, математический и вычислительный подход к неопределенному выводу.Чтобы проводить эффективные рассуждения в реальных обстоятельствах, программное обеспечение ИИ должно надежно справляться с неопределенностью. Однако предыдущие подходы к неопределенному выводу не обладают широтой охвата, необходимой для обеспечения комплексного рассмотрения разрозненных форм когнитивно-критической неопределенности, поскольку они проявляются в различных формах прагматического вывода. Выходя за рамки предшествующих вероятностных подходов к неопределенному выводу, PLN может охватить в рамках неопределенной логики такие идеи, как индукция, абдукция, аналогия, нечеткость и спекуляция, а также рассуждения о времени и причинности.
Рассуждения о биологическом взаимодействии
Существует множество баз данных, обозначающих взаимодействия между генами, белками, химическими соединениями и другими биологическими объектами. Некоторые из них недавно были импортированы в формат OpenCog AtomSpace (после некоторого написания сценариев для их переформатирования), поэтому они готовы к рассуждению об использовании PLN.
Некоторые из них недавно были импортированы в формат OpenCog AtomSpace (после некоторого написания сценариев для их переформатирования), поэтому они готовы к рассуждению об использовании PLN.
Примером ценности такого рода рассуждений может быть: использование вывода по аналогии для приблизительной передачи знаний от одного организма к другому, т.е.г. мухи или мыши для людей.
- Хорошо подходит для семестра кода; Эдди Монро мог бы быть наставником
Планирование через временную логику и проверку согласованности
Общий и элегантный способ планирования с использованием злотых:
- Используйте явную временную логику, чтобы временные зависимости между различными действиями явно кодировались в атомах с использованием таких отношений, как «До», «После», «Во время» и т. Д.
- Улучшите обратную цепочку так, чтобы, когда она порождает новую ссылку в своем В процессе связывания он проверяет, согласуется ли эта ссылка логически с другими многообещающими ссылками, находящимися в другом месте в дереве обратной цепочки. .. (где, если A и B являются неопределенными, логическая несогласованность означает, что (A и B) имеет гораздо более низкую силу истинности, чем можно было бы ожидать, исходя из предположения независимости.)
 .. (где, если A и B являются неопределенными, логическая несогласованность означает, что (A и B) имеет гораздо более низкую силу истинности, чем можно было бы ожидать, исходя из предположения независимости.)
.. (где, если A и B являются неопределенными, логическая несогласованность означает, что (A и B) имеет гораздо более низкую силу истинности, чем можно было бы ожидать, исходя из предположения независимости.)Поиск логической непротиворечивости может быть выполнен эвристически начиная с вершины дерева обратного вывода и двигаясь вниз. Если быстрый вывод говорит, что определенная ссылка L согласуется со ссылкой в определенном узле N в BIT, тогда проверка согласованности с дочерними элементами N, вероятно, не требуется.
Этот подход включил бы эвристику, обычно используемую в алгоритмах планирования, в обычно разумный метод управления логическим выводом ...
Но, несмотря на концептуальную простоту, это потребует значительных усилий для реализации .... Итак, в ближайшем будущем Джейд работает над более простым планировщиком в пространстве состояний, расширяющим нынешний грубый планировщик ....
Пространственное и временное мышление
Код существует для выполнения временных рассуждений в PLN с использованием нечеткой / вероятностной версии алгебры интервалов Аллена. Однако этот код мало использовался. Важно создать хороший набор тестов для временного мышления.
Однако этот код мало использовался. Важно создать хороший набор тестов для временного мышления.
Построение аналогичной системы для пространственного мышления с использованием исчисления связей регионов также является нерешенной задачей.
Но для начала нам понадобится работающий SpaceServer.
Объединение PLN и MOSES
Интегрируйте контролируемую категоризацию на основе MOSES в PLN, чтобы, когда цепочка PLN попадает в запутанную точку, она может запускать MOSES для изучения шаблонов в элементах атомов на текущем конце цепочки (что затем может предоставить дополнительную информацию, полезную при сокращении ).(1)
Вывод на основе истории
Заставляет логический вывод прямой и обратной цепочки PLN использовать историю - так что шаг вывода с большей вероятностью будет выполнен, если аналогичные шаги были предприняты в аналогичных случаях. (1)
Некоторые заметки о том, как это сделать, написанные в начале мая 2012 года в контексте того, что Динцзе Ван потенциально может начать работу над этой темой .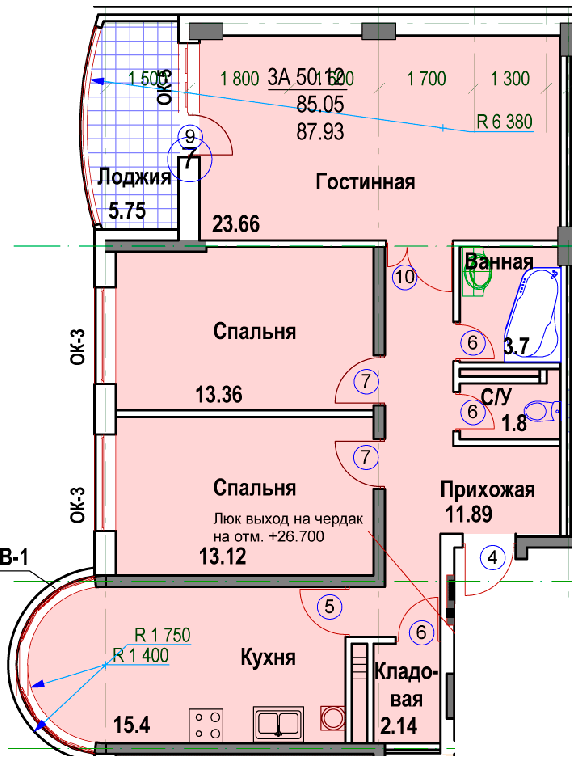 ..
..
Вот пример шаблона дерева вывода, который может быть извлечен из хранилища данных деревьев вывода:
Последствия
И
Оценка меня ориентирует
Оценка застряла меня
Оценка рядом (мне $ X)
СходствоСсылка $ X $ Y
Оценка
UsefulForInference
СходствоСсылка $ X $ Y
Для простоты назовем этот паттерн «P1»...
В этом шаблоне P1 неофициально говорится: «Если я застрял и нахожусь рядом с $ X, а $ X похож на $ Y ... тогда выводы с участием (SimilarityLink $ X $ Y) могут быть полезны. .. "
Если бы у нас были ContextLinks, лучшая версия вышеперечисленного была бы
ContextLink
навигация
Последствия
И
Оценка застряла меня
Оценка рядом (мне $ X)
СходствоСсылка $ X $ Y
Оценка
UsefulForInference
СходствоСсылка $ X $ Y
, но на данный момент подойдет версия P1 без ContextLink...
Для первоначального исследования в контексте навигации соответствующая форма шаблона будет просто
Последствия
И
Оценка застряла меня
Оценка рядом (мне $ X)
СходствоСсылка $ X $ Y
Оценка
UsefulForInference
СходствоСсылка $ X $ Y
Концептуальное определение предиката UsefulForInference (который еще не существует в коде или в книге PLN):
Оценка UsefulForInference W
означает, что выполнение вывода с использованием W с большей вероятностью увеличит скорость или качество вывода вывода.
Практическое определение UsefulForInference:
Оценка UsefulForInference W
означает, что W чаще встречается в "хороших" суб-тегах, чем "плохих" суб-тегах, в архивных тегах логического вывода, которые были сохранены для анализа.
Целью управления выводом на основе истории является изучение шаблонов, подобных P1, из исторической базы данных пар фирмы.
(dag вывода, контекст dag вывода)
«Контекст» тега вывода состоит из атомов, на которые ссылается этот тег, и других связанных с ними атомов.
Чтобы сделать обучение легко управляемым, мы сначала хотим указать задействованные предикаты. Пространственные предикаты - хорошее начало, если исходным контекстом изучения является навигация по PLN. В приведенном выше примере использовалось слово «застрял» - мы можем захотеть изобрести некоторые другие предикаты, представляющие практические контексты, в которые система может попасть во время навигации.
Использование контекста здесь усложняет вещи, но также делает их более реалистичными и мощными. У людей управление логическими выводами действительно зависит от контекста и от паттернов, изученных посредством анализа взаимосвязей между выводами и их контекстами.
Мне кажется, что изучение паттернов можно разумно проводить с помощью MOSES, воздействуя на программные деревья ограниченной формы. Для начала, возможно, мы могли бы посмотреть на шаблоны ограниченной формы
Последствия
И
Link_1 targ_11 targ_12
...
Link_k targ_k1 targ_k2
Оценка
UsefulForInference
И
Link_ (k + 1) targ_ (k + 1) 1 targ_ (k + 1) 2
...
Link_ (k + r) targ_ (k + r) 1 targ_ (k + r) 2
, где целями могут быть конкретные атомы или переменные... и изначально k и r были бы довольно маленькими ...
Шаги к реализации этого выглядят так:
1) Создайте механизм для хранения группы пар (логический вывод, контекст) [возможно, в Atomspace?]
2) Проведите кучу экспериментов по навигации PLN в разных ситуациях и сохраните теги вывода и контексты
3)
Проведите базовый статистический анализ этого хранилища данных и контекстов вывода, чтобы понять его.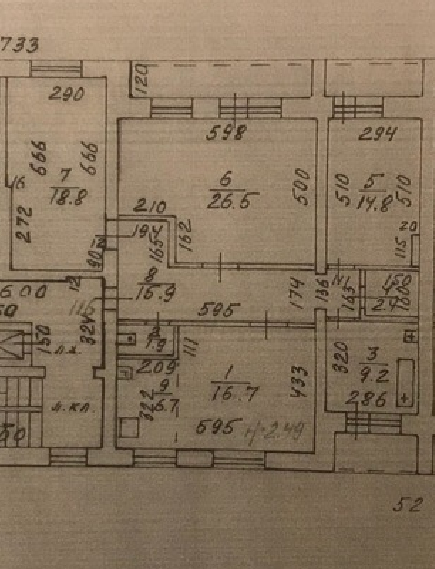
4) Настройте MOSES для использования входов и ограниченной функциональной формы, необходимой для изучения вышеперечисленных типов шаблонов (например, P1)
5) Примените MOSES и посмотрите, какие шаблоны он изучает
NLP используется в OpenCog двумя разными способами.Во-первых, существующая инфраструктура, состоящая из Link Grammar и RelEx, используется для предоставления необработанных данных для когнитивной обработки более высокого уровня. Один из текущих проектов - использование вывода Relex2Logic с PLN для выполнения рассуждений.
Другой основной областью внимания является изучение языка без учителя. Предложение для этого описано в документе: Изучение языка из большого (неаннотированного) корпуса на ArXiv. Более подробно этот проект описан на вики-странице изучения языков.На этой странице описано несколько проектов-кандидатов GSOC-2015 .
Хотя NLP и понимание языка являются основными направлениями OpenCog, многие инструменты языкового конвейера в настоящее время не входят в базовую структуру OpenCog и вместо этого выполняют большую предварительную обработку, прежде чем передавать свои результаты в OpenCog AtomSpace для рассуждений и обучения. В конечном итоге мы планируем перенести эту обработку NLP в ядро, чтобы правила языка могли обновляться на основе опыта. Текущий, фактически существующий конвейер НЛП описан здесь.
В конечном итоге мы планируем перенести эту обработку NLP в ядро, чтобы правила языка могли обновляться на основе опыта. Текущий, фактически существующий конвейер НЛП описан здесь.
Ниже приведены некоторые дополнительные связанные проекты НЛП, за которыми стоит заняться.
RelEx
RelEx - это англоязычный экстрактор семантических отношений, построенный на синтаксическом анализаторе ссылок Карнеги-Меллона. Он может идентифицировать субъект, объект, косвенный объект и многие другие отношения между словами в предложении. Он также может обеспечивать тегирование части речи, тегирование числа существительных, тегирование времени глагола, тегирование пола и т. Д. Relex включает базовую реализацию алгоритма разрешения анафоры (местоимения) Хоббса.При желании он может использовать GATE для обнаружения сущностей. RelEx также обеспечивает формирование семантических отношений, аналогичное FrameNet.
Выходными данными RelEx является гиперграф узлов и ссылок, которые вводятся в OpenCog и затем могут обрабатываться различными способами.![]() Кроме того, пакет LexAt (lexical attaction) предоставляет множество скриптов и инструментов баз данных для сбора статистической информации о проанализированных предложениях.
Кроме того, пакет LexAt (lexical attaction) предоставляет множество скриптов и инструментов баз данных для сбора статистической информации о проанализированных предложениях.
В настоящее время RelEx принимает предложение и выводит набор логических отношений, выражающих семантику предложения.Можно взять логические отношения, извлеченные из нескольких предложений, и объединить их с помощью механизма логических рассуждений, чтобы увидеть, какие выводы можно сделать. Так, например, англоязычный ввод Аристотель - мужчина. Люди смертны. должно позволить сделать вывод . Аристотель смертен.
Некоторые экспериментальные прототипы в этом направлении были выполнены в 2006 году с использованием предложений, содержащихся в рефератах PubMed (см. Статью). Но систематического программного подхода не применялось.
Эти эксперименты можно проводить в различных механизмах правил, включая вероятностные логические сети, а также в более стандартных механизмах четких правил, таких как SWIRLS.
Этот проект подходит для студентов, которые интересуются как компьютерной лингвистикой, так и логическим выводом, а также имеют некоторые знания в области логики предикатов.
Простой, но подробный пример вывода на основе языка с использованием RelEx и PLN приведен здесь: Файл: RelEx PLN Пример Inference.pdf.
Соответствующие рабочие примечания можно найти в дереве исходного кода OpenCog в каталогах opencog / nlp / seme / README и opencog / nlp / triples / README.
См. Также трубопровод NLP-PLN-NLGen.
- Хорошо подходит для семестра кода; Аминь или Космо могут наставить
Улучшенное справочное разрешение
Эталонное разрешение (разрешение анафоры) - это проблема определения того, к каким словам относятся такие слова, как «он», «он» и «она». Есть несколько способов решения этой проблемы.
1. Статистические методы : Текущая реализация RelEx использует для этого алгоритм Хоббса , который является интеллектуальным, но грубым механизмом, который обеспечивает точность около 60%.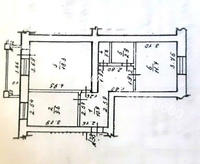 Комбинируя алгоритм Хоббса со статистическими измерениями (один из которых иногда называют баллом Хоббса ), должно быть возможно (согласно литературным результатам) получить точность до 85% или около того. Подходит для всех, кто хочет получить практический опыт работы со статистической лингвистикой корпуса.
Комбинируя алгоритм Хоббса со статистическими измерениями (один из которых иногда называют баллом Хоббса ), должно быть возможно (согласно литературным результатам) получить точность до 85% или около того. Подходит для всех, кто хочет получить практический опыт работы со статистической лингвистикой корпуса.
2. Рассуждение : предложения обычно содержат утверждения, точность которых можно проверить. Так, например: Жюль уехал в Париж. Он много чего видел там. например
- Относится ли he к Жюлю или Парижу?
- Может ли Джулс видеть вещи?
- Париж может видеть вещи?
- там относится к Парижу или Жюлю?
- Можно много чего увидеть в Жюле?
- Можно много чего увидеть в Париже?
Этот подход более эффективен, чем статистический, но требует создания обширной базы знаний и последующего анализа PLN.
Например: текущий код RelEx «знает», что «он» не может относиться к «Парижу», потому что он знает, что «он» - местоимение мужского рода, а Париж - это местоположение. Он знает, что «Жюль» - мужское начало, и поэтому может предложить это в качестве решения.
Он знает, что «Жюль» - мужское начало, и поэтому может предложить это в качестве решения.
Напротив, Relex не знает, кто или что может «видеть» вещи. Потребуется значительная работа, чтобы создать базу данных «видимых» вещей. Такая база данных может быть построена путем сбора определенных простых грамматических конструкций ... например, разбор большого корпуса и поиск всех вхождений «X видел Y» и запоминание X и Y для последующего использования в рассуждениях.
3. Теория дискурса : В теории дискурса проводится различие между темой и ремой : о чем говорят и что говорят.В приведенном выше примере «Жюль» - это тема, а его поездка - это рема: разговор сосредоточен на Жюле. Таким образом, уместно предположить, что «он» обязательно должен относиться к «Жюлю», а не к «Парису», просто потому, что «Жюль» является темой разговора. Порядок слов и другие синтаксические явления могут помочь прояснить, о чем идет речь. Таким образом, теория дискурса обеспечивает косвенный, но действенный способ помощи в разрешении референций и, в частности, устранении неоднозначности между равнозначными вариантами выбора.
Задача состоит в том, чтобы обнаружить фокус внимания в разговоре и использовать его для определения справочного разрешения. См., Например: Гросс, Джоши, Вайнштейн (1994) «Центрирование: структура для моделирования согласованности дискурса»
OpenCog, а не RelEx: В любом из этих случаев работа будет выполняться в OpenCog AtomSpace с использованием схемы или агентов Python MindAgents. Было бы очень мало или вообще не было бы усилий по расширению текущего Java-кода в RelEx.Причина этого в том, что OpenCog имеет (будет иметь) доступ к большой базе данных и инструментам рассуждений для работы с ней; RelEx этого не делает.
Ссылка на синтаксический анализатор грамматики
Было бы полезно внести ряд улучшений в парсер Link Grammar.
Изучите контрольную транзитивность в грамматике ссылок
Грамматика ссылок использует ограничение «плоских графов» (, т.е. без пересечений ссылок), чтобы исключить необоснованный синтаксический анализ.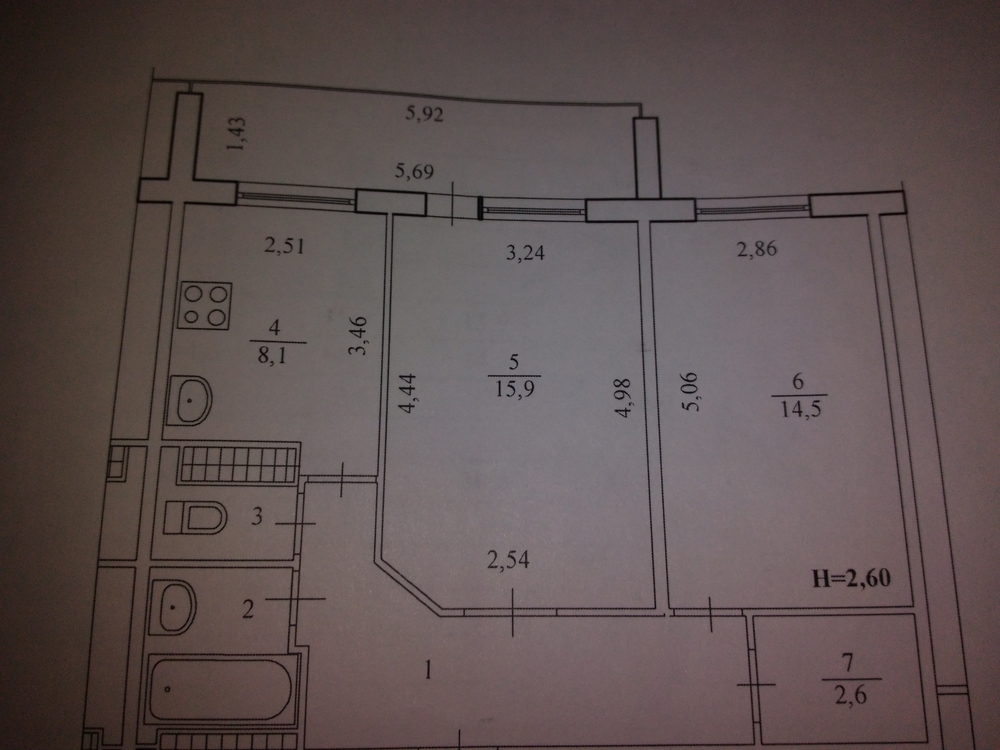 Кажется, что можно было бы заменить это правило понятием «Транзитивность ориентира», взятым из Грамматики слов Хадсона.Основная идея такова:
Кажется, что можно было бы заменить это правило понятием «Транзитивность ориентира», взятым из Грамматики слов Хадсона.Основная идея такова:
Каждой ссылке грамматики ссылок заданы отношения «родитель-потомок»: один конец ссылки является родительским, а другой - дочерним. Так, например, если существительное связано с модификатором существительного, существительное является родителем ссылки. Тогда родители - ориентиры для детей. К этим родительско-дочерним отношениям применяется транзитивность (в математическом смысле «транзитивные отношения»). В частности, правило без перекрестных ссылок заменяется двумя основными правилами транзитивности:
- Если B является ориентиром для C, то A также является ориентиром типа L для C
- Если A является ориентиром для C, то B также является ориентиром для C
, где type-L означает прямую или левую ссылку.
Бен предполагает, что добавление транзитивности Landmark могло бы устранить большую часть или все правила пост-обработки Link Grammar. См. Подробности в грамматике Бена PROWL. См. Также Обработка естественного языка ниже.
См. Подробности в грамматике Бена PROWL. См. Также Обработка естественного языка ниже.
- Хорошо подходит для семестра кода; Бен и Линас могут быть наставниками
Разбор грамматики слов
Внедрите синтаксический анализатор грамматики слов, который использует словарь грамматики ссылок. Это создает сильное впечатление, что это подход к пониманию NL, подходящий для общего интеллекта.
Следующим шагом будет использование PLN для семантического смещения синтаксического анализа.
- Хорошо подходит для семестра кода; Бен или Линас могут быть наставником
Контекстно-зависимый синтаксический анализ
Реализовать поддержку «речевых регистров», таких как заголовки газет, медицинские заметки, детские книги, разговорная речь. Стиль языкового выражения варьируется в зависимости от контекста: например, в заголовках газет часто опускаются статьи. В детских книгах часто используются архаичные грамматические конструкции, которые обычно не используются во взрослой письменной форме.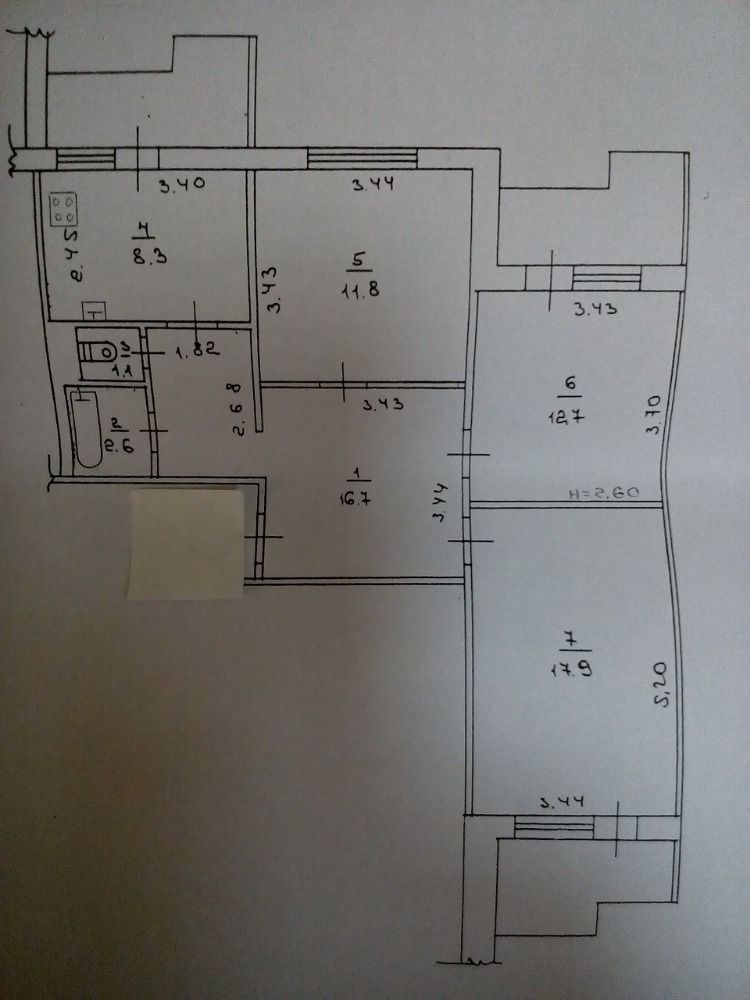 Во время разговорной речи правила грамматики значительно смягчаются; продолжительные предложения могут преобладать. Таким образом, универсальный набор правил грамматики имеет проблемы с этими ситуациями, поскольку правила грамматики, подходящие для одного контекста, могут не подходить для другого. Ослабление правил синтаксического анализа, достаточное для работы с заголовками газет или чатом, приведет к тому, что правила будут слишком свободными для текста книги или газеты, что приведет к чрезмерному количеству неправильных синтаксических анализов. Таким образом, лучший подход - применить другой набор грамматических правил в зависимости от контекста.
Во время разговорной речи правила грамматики значительно смягчаются; продолжительные предложения могут преобладать. Таким образом, универсальный набор правил грамматики имеет проблемы с этими ситуациями, поскольку правила грамматики, подходящие для одного контекста, могут не подходить для другого. Ослабление правил синтаксического анализа, достаточное для работы с заголовками газет или чатом, приведет к тому, что правила будут слишком свободными для текста книги или газеты, что приведет к чрезмерному количеству неправильных синтаксических анализов. Таким образом, лучший подход - применить другой набор грамматических правил в зависимости от контекста.
Один из способов сделать это - отрегулировать «стоимость» использования определенных ссылок в различных ситуациях. Так, например, пропуск определителей, таких как «the» или «a», может быть очень высоким при анализе обычного текста, но затраты будут низкими при анализе заголовков газет.
Этот проект требует разработки измененных правил грамматики, которые могут начать работать с некоторыми из этих различных «речевых регистров». t также требует расширения системы подсчета очков, чтобы в разных ситуациях использовались разные наборы затрат.
t также требует расширения системы подсчета очков, чтобы в разных ситуациях использовались разные наборы затрат.
Более интересным вариантом было бы, пожалуй, распознавание контекста по входному тексту. Так, например, блок среднеанглийского текста будет очень плохо разбираться с использованием стоимости синтаксического анализа на современном английском языке; один и тот же текст с назначенной стоимостью, соответствующей среднему английскому языку, приведет к низкой стоимости: по сути, разные системы оценки действуют как классификаторы для анализируемого текста.
Это сложная и трудоемкая задача, в основном потому, что создание статей словаря грамматики ссылок вручную очень сложно, требует много времени и подвержено ошибкам.Эту задачу можно было бы лучше решить после того, как задача изучения языка без учителя даст результаты.
Цитируемый текст, длинная структура, иерархическая структура
В настоящее время Link Grammar не может правильно обрабатывать цитируемый текст и диалоги.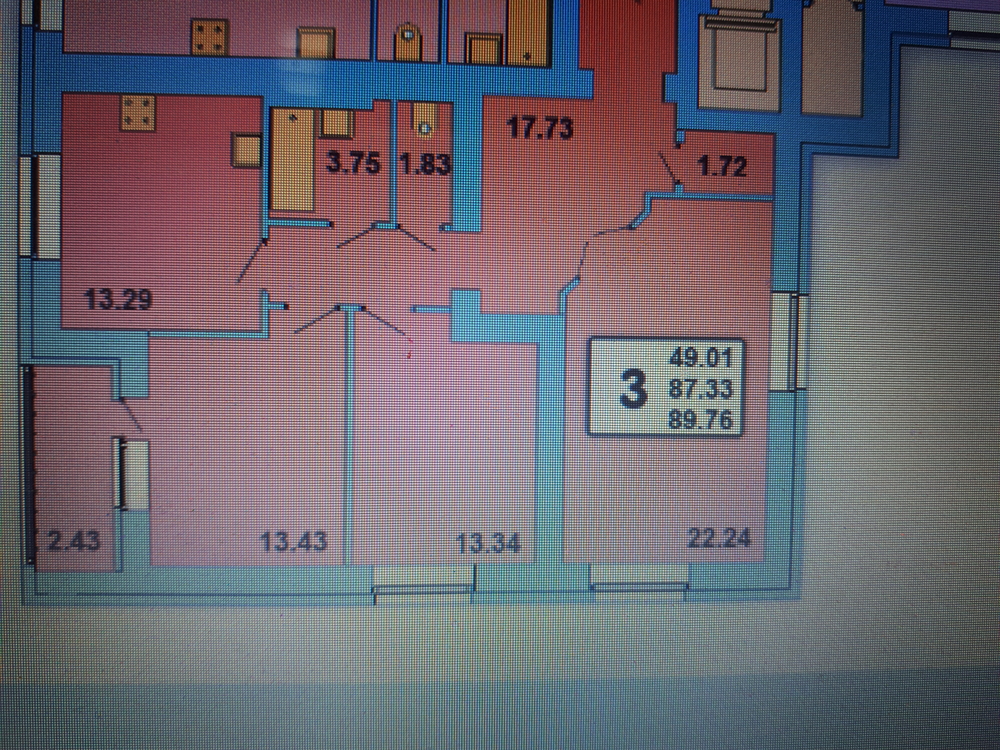 Необходим механизм, чтобы отделить цитату от цитируемого текста, чтобы каждый из них можно было соответствующим образом проанализировать. Это может быть сделано с некоторой предварительной обработкой (например, в RelEx) или, возможно, внутри самой Link Grammar.
Необходим механизм, чтобы отделить цитату от цитируемого текста, чтобы каждый из них можно было соответствующим образом проанализировать. Это может быть сделано с некоторой предварительной обработкой (например, в RelEx) или, возможно, внутри самой Link Grammar.
Непонятно, как с этим справиться в грамматике ссылок.Это в некоторой степени связано с проблемой морфологии (анализ слов, как если бы они были "мини-предложениями") идиомами (фразами, которые обрабатываются как отдельные слова), структурами фраз-наборов (если ... то ... не только ... но также ...), которые имеют структуру дальнего действия, похожую на цитируемый текст (он сказал ...)
- Хорошо подходит для семестра кода; Линас, Рутинг или Родас могли бы наставлять
Статистически похожие выражения для ответов на вопросы
Правильный вывод на основе языка требует, чтобы подобные выражения распознавались как таковые.Например, X является автором Y и X написал Y являются более или менее синонимичными фразами. Лин и Пантел описывают, как автоматически обнаруживать такие похожие фразы (см. Деканг Лин и Патрик Пантел. 2001. «Обнаружение правил вывода для ответа на вопросы». Natural Language Engineering 7 (4): 343-360). Аналогичный, но более изощренный подход предложен Хойфунг Пун и Педро Домингос, 2009, «Неконтролируемый семантический анализ».
Лин и Пантел описывают, как автоматически обнаруживать такие похожие фразы (см. Деканг Лин и Патрик Пантел. 2001. «Обнаружение правил вывода для ответа на вопросы». Natural Language Engineering 7 (4): 343-360). Аналогичный, но более изощренный подход предложен Хойфунг Пун и Педро Домингос, 2009, «Неконтролируемый семантический анализ».
Обе эти системы используют статистические методы для поиска часто встречающихся подвыражений.Оба начинаются с текста, обработанного анализатором зависимостей. В то время как первый ищет цепочки грамматических отношений зависимости, которые можно рассматривать как синонимы, второй ищет произвольные шаблоны, которые могут быть сгруппированы в один и тот же «синоним» или «концепт». Эти две статьи также различаются статистическими мерами, используемыми для отнесения синонимичных паттернов к общему кластеру, но не ясно, какой статистический метод лучше, и имеет ли это даже большое значение. Линь использует меры, основанные на взаимной информации, а Домингос применяет теорию логических сетей Маркова.
Целью этой задачи было бы внедрение системы частого анализа шаблонов в инфраструктуре OpenCog. То есть, учитывая большое количество гиперграфов OpenCog, необходимо идентифицировать общие подграфы, а затем, используя некоторую статистическую меру (например, взаимную информацию, или, возможно, MLN, или другую меру расстояния), такие гиперграфы будут сгруппированы вместе. Каждый такой обнаруженный кластер можно рассматривать как «концепт»; элементы кластера являются «синонимичными выражениями концепции».
В идеале, ища не только синонимы, но и общие шаблоны в целом, система, надеюсь, автоматически найдет «речевую формулу» или, возможно, «лексические функции», как описано в теории смыслового текста Мелчука. Предположительно, такие методы кластеризации также должны иметь возможность группировать похожие вещи, например кластер, содержащий названия музыкальных инструментов и т. Д.
Обнаружение таких кластеров должно быть полезно как для ответов на вопросы, так и для генерации естественного языка (поскольку кластеры могут содержать разные способы выражения одной и той же «идеи». )
)
Генерация естественного языка
TODO. См. SuReal, MicroPlanning и SegSim.
Другие подходы к созданию языка включают в себя работу Маркуса Гуэ (2003) «Инкрементальная концептуализация для производства языка»
DeSTIN расшифровывается как Deep SpatioTemporal Inference Network и представляет собой масштабируемую архитектуру глубокого обучения, основанную на сочетании обучения без учителя и байесовского вывода. Имеется статья изобретателей этого метода.Он хорошо подходит для того, чтобы стать модулем видения OpenCog, и был принят проектом для очистки кода для выпуска как OSS. DeSTIN реализован на CUDA.
Несколько человек уже работают над DeSTIN, но привлечение кого-то, кто будет помогать с упаковкой, внедрять среду тестирования с использованием CTest и / или создавать привязки к языку Python, поможет развить ее в самостоятельный стоящий проект.
Использование DeSTIN и SVM или нейронных сетей для эффективной классификации изображений
DeSTIN можно использовать в качестве генератора признаков для контролируемой классификации изображений с помощью таких инструментов, как SVM, Neural Nets или MOSES.
Некоторая работа была проделана с использованием, например, корпус классификации изображений CiFAR. Но достигнутая пока точность не так уж и высока. Было бы хорошо, если бы кто-то сосредоточился на настройке и настройке DeSTIN, а также на соответствующей предварительной обработке изображений, чтобы повысить точность классификации. Это полезно, потому что это способ научить нас настраивать DeSTIN, чтобы он работал лучше в целом.
Подключение DeSTIN и OpenCog
Вот одна идея с использованием искусственного интеллекта для проекта с участием DeSTIN (автор Ben Goertzel)
Я хочу передать данные с веб-камеры в DeSTIN, а затем (в абстрактная форма) в OpenCog.Игрушечные проблемы вроде MNIST на самом деле не являются мне интересно, потому что цель моих исследований в данном контексте - робот видение. Так что масштабируемость важна.
Между DeSTIN и OpenCog будет «умный интерфейс», который будет в основном
- запись базы данных векторов состояний DeSTIN
- определить закономерности в этой базе данных с помощью машинного обучения алгоритмы
- вывести эти шаблоны в вероятностную / символьную базу знаний OpenCog
Вот несколько подробных идей о том, как это потенциально сделать
Цель - получить действительно простые вещи
работать, как
- кормить ДеСТИН фотографии автомобилей, мотоциклов, велосипедов, унициклов и грузовики (видео было бы здорово, но начнем с картинок)
- посмотрите, приводит ли вся система к тому, что OpenCog получает ConceptNodes для автомобиль, мотоцикл, велосипед, одноколесный велосипед и грузовик с соответствующими логическими связи между ними как
Наследование автомобиля motor_vehicle <. 9>
9>
Наследственный грузовик motor_vehicle <.9>
Наследование велосипеда motor_vehicle <.1>
Сходство велосипедного одноколесного велосипеда <.7>
Сходство велосипедного мотоцикла <.7>
Сходство мотоцикла автомобиля <.6>
Сходство велосипедного автомобиля <.3>
Обратите внимание, что хотя здесь я использую английские термины, в этом эксперименте OpenCog ConceptNodes не будет иметь английских имен и английских слов вообще не будет задействован - я просто использую английские термины как сокращения.
Это будет первый пример объединения субсимволических символов DeSTIN. знания и символические знания OpenCog, что было бы довольно круто и хороший старт для дальнейшей работы над интеллектуальным зрением;)
Смешивание
Реализуйте концептуальное смешение как эвристику для объединения концепций с функцией соответствия для вновь сформированной концепции, включающей качество выводимых выводов, полученных из концепций, и качество правил классификации MOSES, изученных с использованием концепции.
Распределение внимания и психопатология
Можно провести некоторые любопытные параллели между динамикой распределения внимания и различными психическими расстройствами человека. Аналогии с человеческими психологическими проблемами не следует воспринимать всерьез; это был скорее способ размышления о различных динамических явлениях, которые можно было наблюдать, соответствующим образом изменяя параметры распределения внимания и его связи с OpenPsi ...
...
- Одержимость.Слишком долго сосредотачиваться на чем-то одном. Этого можно достичь, если не задерживать STI атомов в AttentionalFocus достаточно быстро. Это должно привести к тому, что все больше и больше HebbianLink будет построено между атомами в AF, что еще больше усилит навязчивую идею.
- Синдром дефицита внимания. Неспособность ни на что обращать внимание. Это может быть достигнуто за счет слишком быстрого распада STI атомов в AF. Не так много сильных ассоциаций усваивается, потому что ничто не остается в AF так долго. Однако, если ум находится в ситуации, когда множество стимулов постоянно поступает из некоторого связного контекста, тогда ум будет уделять внимание этому же контексту на некоторое время и строить ассоциации относительно него; это похоже на то, как люди с СДВ часто могут хорошо сосредотачиваться на видеоиграх или других контекстах, включающих богатые быстрые потоки данных и полное взаимодействие.
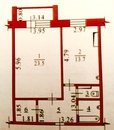 Однако, если ум находится в ситуации, когда множество стимулов постоянно поступает из некоторого связного контекста, тогда ум будет уделять внимание этому же контексту на некоторое время и строить ассоциации относительно него; это похоже на то, как люди с СДВ часто могут хорошо сосредотачиваться на видеоиграх или других контекстах, включающих богатые быстрые потоки данных и полное взаимодействие.
Однако, если ум находится в ситуации, когда множество стимулов постоянно поступает из некоторого связного контекста, тогда ум будет уделять внимание этому же контексту на некоторое время и строить ассоциации относительно него; это похоже на то, как люди с СДВ часто могут хорошо сосредотачиваться на видеоиграх или других контекстах, включающих богатые быстрые потоки данных и полное взаимодействие.- Гипермания. * Это могло бы произойти, если бы разум становился очень доволен каждой новой вещью, которая входила в его AF, но затем быстро становился недоволен этим впоследствии.Итак, новизна должна быть очень взвешенной целью; возможно, цель будет сформулирована как выполненная, если у новизны будет высокий уровень STI.
- Депрессия. * Один из видов депрессии связан с зацикливанием на несчастных мыслях. Это может произойти, если: 1) определенные несчастные мысли (мысли, связанные с низким уровнем удовлетворения) находятся в AF какое-то время, 2) все, что проходит через AF, получает HebbianLinks, созданное для этих несчастных мыслей, 3) вывод PLN еще строится больше связей между Атомами и несчастными мыслями; 4) все эти HebbianLinks затем возвращают несчастные мысли в AF, когда другие вещи, связанные с несчастными мыслями, находятся в AF. ..
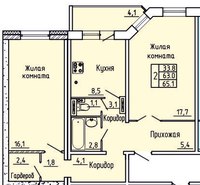 ..
..Формирование карты
Реализуйте «формирование карты», процесс, который использует частые методы анализа подграфов для поиска часто встречающихся подсетей AtomTable, а затем воплощает их в качестве новых узлов. Это требует некоторого расширения и адаптации текущих алгоритмов для частого поиска подграфов. Это также требует функционального распределения внимания.
Формирование контекста
Реализуйте формирование контекста, в котором атом C определяется как контекст, если он важен, а ограничение других атомов A контекстом C приводит к выводам, которые значительно отличаются от значения истинности A по умолчанию.
Кластеризация
См. Кластеризацию
Эти проекты связаны с поддержкой воплощения OpenCog в реальных и виртуальных средах.
Создайте прокси ROS для OpenCog
Расширьте модуль Embodiment OpenCog для связи с физическими роботами, используя ROS: Robot Operating System. Узлы ROS выполняют две функции: они задают связь между собой, а также передают данные в реальном времени между собой.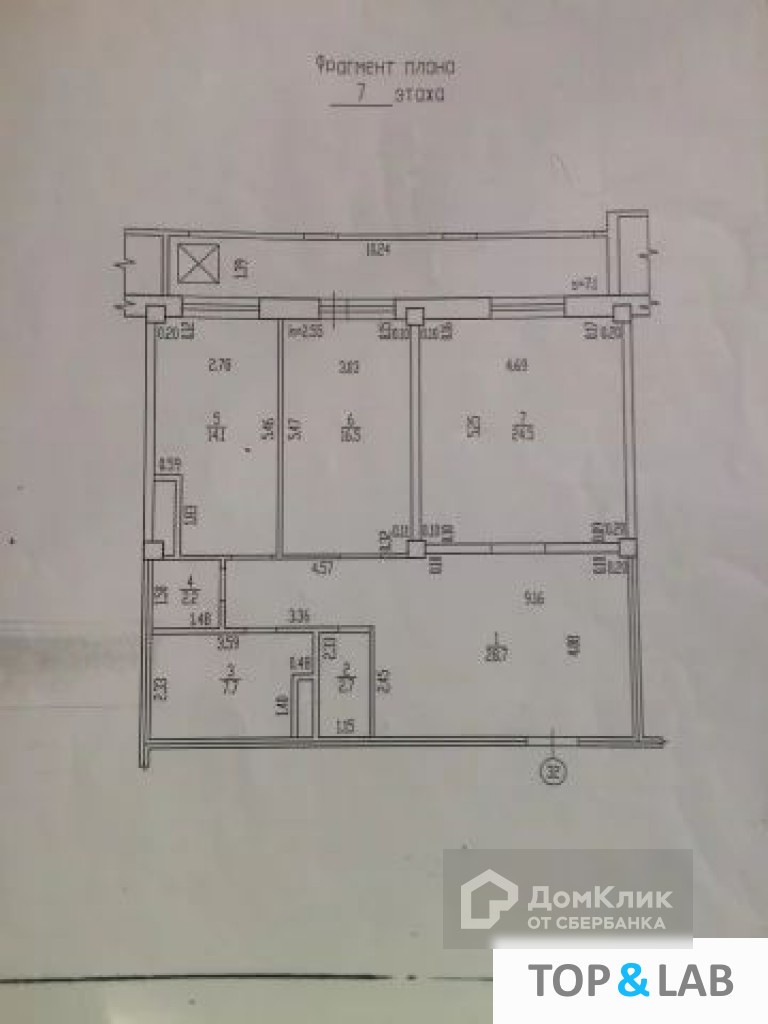 В OpenCog это разделено на две части: атомы используются для указания информации о подключении, а значения хранят быстро изменяющиеся данные в реальном времени.Таким образом, прокси-сервер ROS может состоять из двух частей: нового типа атома ROSNode и соответствующего класса C ++ для него, который указывает, где находится узел ROS, как он называется и как его можно найти, и значение ROSValue. , опять же, с соответствующим классом C ++, который предоставляет методы доступа к данным для работы с потоком данных - например, чтобы получить последнее значение и вернуть его в PLN, чтобы использовать его во время рассуждений.
В OpenCog это разделено на две части: атомы используются для указания информации о подключении, а значения хранят быстро изменяющиеся данные в реальном времени.Таким образом, прокси-сервер ROS может состоять из двух частей: нового типа атома ROSNode и соответствующего класса C ++ для него, который указывает, где находится узел ROS, как он называется и как его можно найти, и значение ROSValue. , опять же, с соответствующим классом C ++, который предоставляет методы доступа к данным для работы с потоком данных - например, чтобы получить последнее значение и вернуть его в PLN, чтобы использовать его во время рассуждений.
Работа над этим проектом проводилась лабораторией искусственного мозга в Университете Сямынь в Фуцзянь, Китай.
- XIA-MAN: расширяемая интегративная архитектура для интеллектуальной робототехники-гуманоида PDF, Бен Гертцель, Хьюго де Гарис
Создание интерфейса Minecraft для OpenCog
Создайте интеграцию между OpenCog и стабильным, хорошо документированным клиентским API Minecraft с открытым исходным кодом (например, Mineflayer или Spock), чтобы разрешить использование любого сервера, реализующего стандарт Minecraft (включая официальный Minecraft, а также любой открытый -source реализации), чтобы эту существующую стандартную среду можно было использовать для создания сред моделирования для экспериментов с общим искусственным интеллектом без необходимости тратить много времени на разработку нового программного обеспечения для моделирования.
Проект будет включать в себя написание кода интерфейса между клиентским API Minecraft и OpenCog, а также будет включать замену части существующего кода варианта осуществления OpenCog, реализующего обмен сообщениями с внешними системами, на упрощенную и модернизированную реализацию. Проект предоставит возможность использовать концепции проектирования программного обеспечения очередей сообщений, слабой связи и сериализации объектов для внешних потребителей. В идеале кандидат должен иметь опыт работы как на Python, так и на C ++.
Для получения дополнительных идей о том, как это будет выглядеть, обратитесь к этой дипломной работе о Minecraft как среде моделирования для общего искусственного интеллекта: http://tmi.pst.ifi.lmu.de/thesis_results/0000/0073/thesis_final.pdf Обратите внимание, что этот тезис был написан в контексте другого проекта, и многие из решений по реализации, содержащихся в нем, будут отличаться от этого проектного предложения; тем не менее, документ действительно включает много хороших объяснений и примеров, которые дают хорошее общее представление о проблемном пространстве.
Этот проект начат и в настоящее время ищет волонтеров. Если интересно, посетите план разработки ботов Minecraft.
Заключение относительно скелетов и поверхностей объектов в трехмерном игровом мире
Как может игровой персонаж, управляемый OpenCog, в трехмерном игровом мире, реализованном в Unity3D, рассуждать о твердых объектах (представленных либо в виде 3D-моделей, либо в виде сборок кирпичей, подобных Minecraft)?
Один из способов - использовать существующий код OSS для преобразования твердых объектов в скелеты и для идентификации частей поверхности объектов.Эта информация о каркасах и поверхностях затем может быть загружена в механизм PLN (вероятностные логические сети) для рассуждений.
Это хорошо для тех, у кого есть опыт или очень большой интерес, связанный с 3D-моделированием, графикой или программированием игр, а также с OpenCog и логическим выводом.
- Хорошо подходит для семестра кода; Озеро или Шуцзин могут стать наставником
Модуль нового воплощения
См. Модуль New Embodiment, март 2015 г.
В этом разделе перечислены проекты, связанные с использованием компонентов OpenCog для конкретных приложений.
Сокобан
Sokoban был бы хорошей игрушкой для экспериментов с различными методами OpenCog. Так что подключение OpenCog к простому серверу Sokoban кажется целесообразным. MOSES и PLN могут использоваться для Sokoban самостоятельно, но, конечно, интереснее использовать интегративный подход. (1)
Особенности| Аккорды, слова и ноты
SongSelect включает несколько функций, которые, как мы думаем, вы найдете чрезвычайно полезными. Ниже приводится обзор некоторых ключевых функций.
Новый формат листа аккордов - улучшенная компоновка, более быстрое время загрузки!
1: загружается быстрее
Он находится в HTML5, поэтому отображается на экране практически мгновенно. Это делает работу на мобильных устройствах намного удобнее!2: Включает больше музыкальной информации (если возможно)
Новый формат будет включать темп (количество ударов в минуту) и тактовый размер песни под ключевым индикатором в верхнем правом углу.3: Улучшенный внешний вид / макет
При работе с музыкантами (преимущественно гитаристами и пианистами) мы обновили визуальное оформление разделов, чтобы их было легче читать.Изменения включают:- Легко читается / идентифицируется «Этикетка раздела» заглавными буквами и с выравниванием по левому краю
- Музыкальные разделы с отступом
- Аккорды жирным шрифтом
В начало | <Вернуться домой
Найти нужную песню можно быстро и легко.
У вас есть песни, которые вы ищете, и не так много времени на их поиск. Мы с гордостью можем сказать, что наш новый поиск предоставит вам беспроблемный опыт.
Простой поиск
С новой поисковой системой все, что вам нужно сделать, это ввести название песни, автора, часть текста или номер песни CCLI.
Список результатов поиска
Теперь получить доступ к содержанию песни прямо из списка результатов поиска стало проще, чем когда-либо. Нужно сузить результаты поиска? Мы даем вам функции, необходимые для непосредственного перехода к нужной песне.
1. Результаты поиска показывают доступное содержание
Список результатов песни, основанный на вашем поисковом запросе, покажет название песни, авторов и содержание песни, доступное в SongSelect для каждой песни.Содержимое включает образцы песен, тексты песен, листы аккордов, ведущие листы и вокальные листы. Просто выберите значок, соответствующий контенту, к которому вы хотите получить доступ, или выберите название песни, чтобы увидеть все.
2. Сортировать результаты по заголовку и другим параметрам
Список результатов поиска будет автоматически отсортирован по релевантности, но вы также можете выбрать сортировку списка по популярности, рангу CCLI, дате добавления и заголовку.
3. Уточнить результаты
Теперь мы предоставляем вам множество вариантов фильтрации, которые позволяют сузить отображаемые результаты поиска.Выбор кнопки Refine Results позволит вам легко фильтровать по доступному содержимому, языкам, темам и исходному ключу.
В начало | <Вернуться домой
Сохраните ваши любимые песни в списке.
Скорее всего, вы обращаетесь к определенному набору песен более одного раза. Как никогда просто сохранить любимую песню в списке и получить к ней доступ из любого места на сайте.
Добавление песни в избранное.
Теперь вы можете добавить песню в список избранных, щелкнув значок сердца рядом с любой песней.Сделайте это на домашней странице, в списке результатов поиска или даже на страницах сведений о песнях. После того, как вы добавили песню в избранное, на значке сердца рядом с песней появится золотое сердечко, чтобы вы знали, что оно сохранено в списке.
Доступ к избранному из любого места.
Когда вы войдете в систему, вы увидите пункт меню, добавленный вверху страницы, который называется Избранное .
При выборе этого пункта меню откроется список всех песен, которые вы сохранили в избранном, и вы сможете быстро получить доступ к любому контенту, связанному с этой песней.
В начало | <Вернуться домой
Для вашего удобства настроено несколько списков быстрого просмотра.
Темы
Откроется полный список из тем , которые вы можете щелкнуть, чтобы просмотреть песни, соответствующие этой теме. Вы также можете начать вводить текст в поле Search Themes , чтобы отфильтровать список.
Популярные песни
Ранее известный как Top SongSelect Songs , в этом списке будут показаны песни, которые наиболее часто используются в SongSelect.Этот список будет меняться чаще, чем Top CCLI Songs , поскольку он учитывает еженедельное использование, а не предыдущий отчетный период.
Лучшие песни CCLI
Вы можете легко получить доступ к списку лучших песен CCLI , чтобы узнать, что используют другие церкви. Этот список выходит за рамки простого использования в SongSelect и позволяет вам увидеть более широкую перспективу того, о чем церкви сообщали за определенный период времени.
Недавно добавленные
В списке Public Domain будут показаны все песни с авторскими правами Public Domain.Эти песни не будут учитываться при использовании вашей уникальной песни.
Что нового
Мы всегда прилагаем все усилия, чтобы предоставить вам качественный контент для песен, которые вы используете. Когда мы добавляем к песне новые ноты, эта песня появляется в списке What's New .
В начало | <Вернуться домой
.